Object Detection
Object detection is a key deep learning task or technique to provide more information about an image through identifying objects within it. It can use boxes to identify people, signs, cars, defects, biomarkers and other elements using boxes to classify and organize the found objects.
These are vital for manufacturers, automotive, healthcare, and other industries that rely on scalable object detection through deep learning. Using evaluation metrics, a bounding box is produced to identify and segment various objects within the image. This means that everything from retail customer analysis to autonomous vehicles safety features can implement object detection for a range of computer vision tasks.
It is important to distinguish object detection from image segmentation, as image segmentation works on the pixel level to differentiate various objects. This can provide some insight to deep learning algorithms but may require object detection as a core methodology to provide more details.
What is object detection?
Object detection is a deep learning technique to understand objects within an image. Developers can create sophisticated algorithms that help firms detect manufacturing defects, product information, retail behaviours, and other functions through object detection.
The core bounding box methodology can help determine various classes of objects, such as buses, trains, people, birds, etc. within an image or video frame. Various machine learning tasks such as instance segmentation, image captioning, object tracking, etc. can be performed through object detection.

The bounding box itself is a tight rectangle that generally is labelled as (bx, by, bh, bw) to identify and classify various objects. It is also vital to understand when to use non-max suppression, wherein multiple boxes are clubbed into a single maximum IOU box to help with distinguishing the object.
Localization
Localization helps draw a bounding box around the specific object that is detected within an image or video frame. The coordinates for the object can be determined and the box can be determined based on the location.
Classification
The classification of the object will depend on the various types of classes present in the algorithm and training data. Based on the existing information present within the algorithm, the specific classification will be applicable.
Instance segmentation
Every instance of the object can be assigned a class based on the pixel level, through instance segmentation. Developers can design highly sophisticated algorithms keeping instance segmentation in mind.
Method of object detection
There are multiple methods of object detection which can be used to determine the overall object present within the key boundary parameters. Two stage architectures are slower but ideal for detecting certain objects through conventional object region proposal and extraction of proposed region with bounding box.
Sliding window method
Within the sliding window method, the square box is applied and it can shift around the image based on key parameters. The border of the box is determined by sliding around the image to detect key patterns or object descriptors.

Feature based method
The essential features of the object are determined through the image frame by complete analysis. The algorithm can be trained for image edges, corners, structures, etc. and the border can track these from frame to frame.
Deep Learning for Object Detection: Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are the foundation of deep learning for object detection. They are designed to process data with a grid-like topology, such as images, and use convolutional layers to learn spatial hierarchies of features, making them effective for object detection tasks.
Architecture of CNNs for Object Detection
- Convolutional Layers: Apply filters to input images to extract key features like edges and textures.
- Pooling Layers: Down-sample feature maps to reduce spatial dimensions and computational load.
- Fully Connected Layers: Often replaced with region proposal networks (RPNs) or feature pyramid networks (FPNs) to handle different object scales.
- Output Layer: Outputs bounding boxes and class labels, predicting the location and category of each detected object.
Popular CNN Architectures for Object Detection
- YOLO (You Only Look Once): A single-stage object detection model that divides the image into a grid and predicts bounding boxes and class probabilities in real-time.
- SSD (Single Shot MultiBox Detector): Similar to YOLO, SSD predicts bounding boxes and class scores in a single pass using different scales and aspect ratios.
- Faster R-CNN: A two-stage model using RPNs to propose regions and a second stage to classify and refine bounding boxes, known for high accuracy.
Evaluation Metrics
Evaluation metrics are essential for assessing the performance of object detection models, providing a standardized way to compare accuracy and effectiveness.
Common Evaluation Metrics
- Precision and Recall:
- Precision: Measures the accuracy of positive predictions.
- Recall: Measures the ability to identify all relevant instances.
- F1 Score: The harmonic mean of precision and recall.
F1=2×Precision×RecallPrecision+RecallF1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}F1=2×Precision+RecallPrecision×Recall - Intersection Over Union (IOU): Measures overlap between predicted and ground truth bounding boxes.
IOU=Area of OverlapArea of UnionIOU = \frac{\text{Area of Overlap}}{\text{Area of Union}}IOU=Area of UnionArea of Overlap - Mean Average Precision (mAP): Average precision across all classes and IOU thresholds.
mAP=1N∑i=1NAPimAP = \frac{1}{N}\sum_{i=1}^{N}\text{AP}_imAP=N1i=1∑NAPi
where APi\text{AP}_iAPi is the average precision for class iii, and NNN is the number of classes.
Transfer Learning and Fine-Tuning
Transfer learning and fine-tuning improve object detection models, especially when training data is limited.
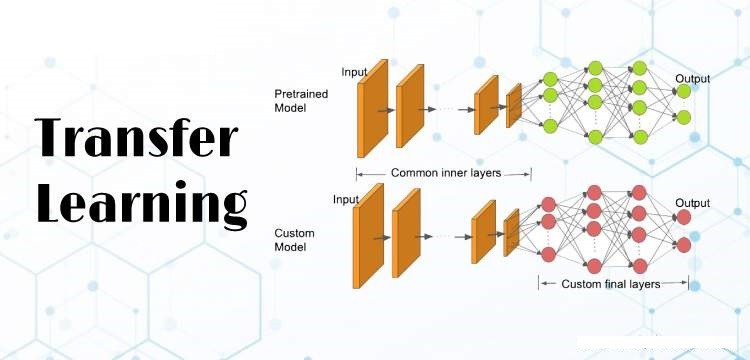
Transfer Learning
- Feature Extraction: Use a pre-trained model as a fixed feature extractor, replacing final layers with new ones for the target task, and training only these layers.
- Fine-Tuning: Train the entire model, including pre-trained layers, with a lower learning rate to adapt to the new task while retaining learned features.
Benefits
- Reduced Training Time: Speeds up the training process by leveraging pre-existing models.
- Improved Accuracy: Provides a strong baseline, improving accuracy with limited data.
- Generalization: Helps models generalize better to new tasks and datasets by building on pre-trained knowledge.Main applications of Object Detection
Applications in Industries
There are several important applications of object detection, which is why there is significant investment in object detection research and analysis. The object detection architectures are designed to detect objects with significant accuracy, especially with a large enough training data and accurate model.
-Surveillance and security
Within the surveillance and security domains, object detection can be leveraged to detect threats, points of intrusion, or locate objects within a security perimeter. Security firms can use deep learning object detection models to perform image classification as well to understand surveying and topography.
-Autonomous vehicles
A key benefit of using a highly trained object detection model is to analyse the input image or video in real-time through computer vision. Architectures such as YOLO and SimpleNet with high mAP accuracies can be deployed to help autonomous vehicles become safer and reliable for daily drivers.
-Retail
Within the retail space, the object detection task is vital to understand and map customer movement and activities. Shelf space time, product feature exploration, time in store, and other metrics can be tracked through object detection and computer vision techniques.
-Healthcare
Healthcare systems can use object detection methods and bounding box regression strategies for object detection tasks involving medical imaging. Patient movement, hospital design, assessments, and post-operative care, can be fully optimized using object detection algorithms.
Challenges in object detection
It is important to understand the key challenges in object detection so that firms are able to provide the right strategic empowerment for better object detection.
-Variations in appearance
The viewpoint variation, or objects viewed from different view points in an image, can introduce greater complexity in detection, labelling, and classification. E.g. if you rotate the image, will the algorithm be able to detect the objects with high enough accuracy is a key question.
-Non-rigid bodies
When algorithms perform object detection, the detected objects may not be rigid enough for a simple model to capture and label. If the training data is used for objects at rest, will they be able to detect objects in motion is a key challenge.
-Complexity in computation
There may be significant complexities in dense object detection and in cases where the visual image may not be of higher resolution. Firms may have to design more complex models and use training data from multiple sources.
-Training data complexities
For autonomous vehicles, as an example, the training data will have to include all types of vehicles, pedestrians, and signs from across the country to ensure optimal safety. The training data complexities will require significant investments and technical engineering for the project.
Future trends in object detection
There are several future trends in object detection models and deep learning, which can enhance the use case optimization across industries and provide more insights to various projects.
-Multiple forms of input data
Object detect dataset optimization will focus on audio, video, text, and other forms of input that will help algorithms improve their detection and classification processes. Firms will be able to get more value from their object detection and image detection models, by focusing on more context.
-Evolution of models
Specific evolutions of models will focus on video object detection, multimodal evolution, and highly complex object detector algorithms in the future. Developers are focused on refining models further to ensure that detection will be performed rapidly on a shorter training data set as well.
-Focus on real time
Ideally, the best object detection models should focus on real-time evolutions of detection and classification. Real time object detection algorithms can provide more information at a faster rate, and is a key area of exploration for developers.
-Greater integration
Future iterations of object detection will emphasize on integration with NLP and reinforcement learning. Computer vision object detection models will be optimized to perfectly blend with language processing models to provide more context to captured images.
FAQs
What are image enhancement AI data management best practices?
Data sources should be diverse, properly transformed, and managed effectively. Data from APIs, data centers, cloud storage, and other sources should be updated regularly to ensure optimal training data effectiveness.
What are consumer use cases for object detection?
Consumers use object detection in applications like home security systems, shopping assistance apps, and augmented reality experiences. These applications rely on accurate object detection to provide valuable insights and enhance user experiences.
How does transfer learning improve object detection models?
Transfer learning allows developers to use pre-trained models and adapt them to new datasets, improving performance and reducing the time and resources needed to train models from scratch.
What is the difference between object detection and image segmentation?
Object detection uses bounding boxes to identify and classify objects within an image, while image segmentation differentiates objects at the pixel level. Both techniques provide valuable insights but serve different purposes in image analysis.
How do advancements in real-time object detection benefit industries?
Real-time object detection models provide immediate insights, enabling quick decision-making and enhancing operational efficiency in industries like automotive, healthcare, and retail.