Object detection enables machines to seek, classify, and locate objects in images or video streams; it is one of the important tasks in computer vision.
Among the models of object detection, YOLO models have gone on to set the benchmark for speed and accuracy in the field.
The latest iteration of YOLO, YOLOX, is a cutting-edge leap in object detection models.
YOLOX learns from the breakdown of the past versions and improves on the best aspects into a powerhouse of accuracy, robustness, and efficiency.
The present study takes a closer look at YOLOX, its architecture, features, advantages, and real-time applications.
We'll also touch on how YOLOX improves the object detection process for usage in computer vision.
The YOLOX Introduction
YOLOX is a next-generation object detection model for faster and more accurate object detection and localization in image input.
YOLOX enhances an architectural and functional evolution from the YOLO family. It remains more than just a transition from predecessors but is designed as an anchor-free system that incorporates dynamic label assignment alongside other features to empower it to handle objects in various sizes, shapes, and scales.
The model uses a single CNN architecture, predicting bounding boxes and class probabilities, and thus providing the location of objects in a single pass through the network.
This makes YOLOX incredibly promising for real-time applications ranging from autonomous driving to video surveillance.
Key Features of YOLOX
Key characteristics, some distinguishing the YOLOX against versions previous to YOLO, and other models for object detection:
1. Anchor-Free Design
YOLOX eliminates the use of predefined anchor boxes, which were used in earlier YOLO models to predict objects of different scales. This anchor-free design simplifies the model architecture, reduces computational overhead, and improves detection accuracy, especially for small objects and objects with irregular object shapes.
2. Dynamic Label Assignment
The traditional YOLO models make use of static label assignment in the training process. As a result, learning is not optimized.
YOLOX employs dynamic label assignment where the matching process between the predicted bounding boxes and the ground truth bounding boxes is dynamically updated in real-time.
This increases detection accuracy for overlapping objects or those that are hard to see.
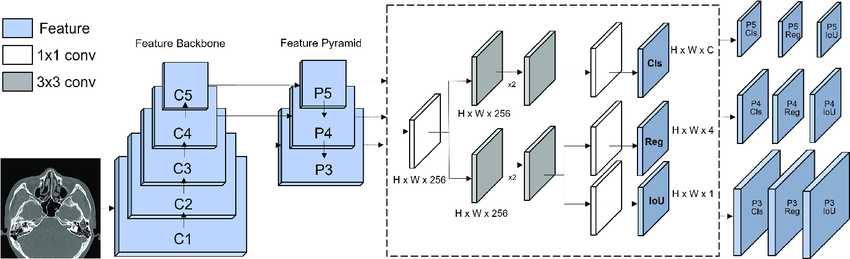
3. Decoupled Head
YOLOX uses a decoupled head structure. That's, the network separates predicting for bounding box coordinates and class probabilities.
This makes the task assigned to distinct branches, allowing YOLOX to produce high-precision object localization as well as classification.
4. Advanced Data Augmentation
Techniques such as MixUp and Mosaic are incorporated into YOLOX to make it more robust. These augmentation techniques blend multiple images during training to make YOLOX generalize better and handle complex situations with ease.
5. Multi-Scale Feature Aggregation
Using a Feature Pyramid Network (FPN), YOLOX aggregates features from multiple scales to improve its ability to detect objects of varying sizes. This is particularly useful for detecting small objects that might otherwise be overlooked.
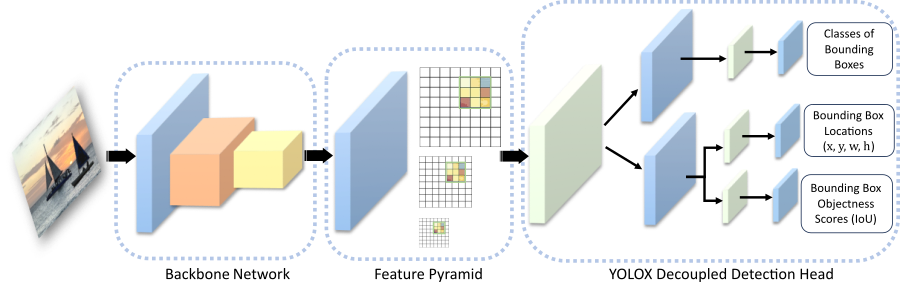
YOLO Architecture Explained
The YOLO architecture is among the most used computer vision frameworks regarding the tasks of object detection. It is used mainly due to its efficiency in producing a pipeline for real-time object detection tasks.
A forward pass of the entire image is allowed, meaning that the whole image can be processed by the model.
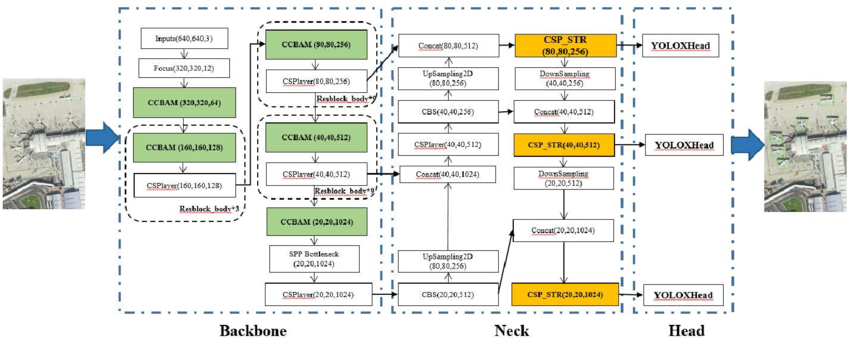
For this reason, it is considered a single-shot object detection model. It includes three major components: the backbone, the neck, and the head.
Core Constituents of YOLO Architecture
1. Backbone
The backbone will take up the job of feature extraction from the input image. It makes use of a convolutional neural network (CNN) that treats the image and brings in feature maps that highlight the possible objects.
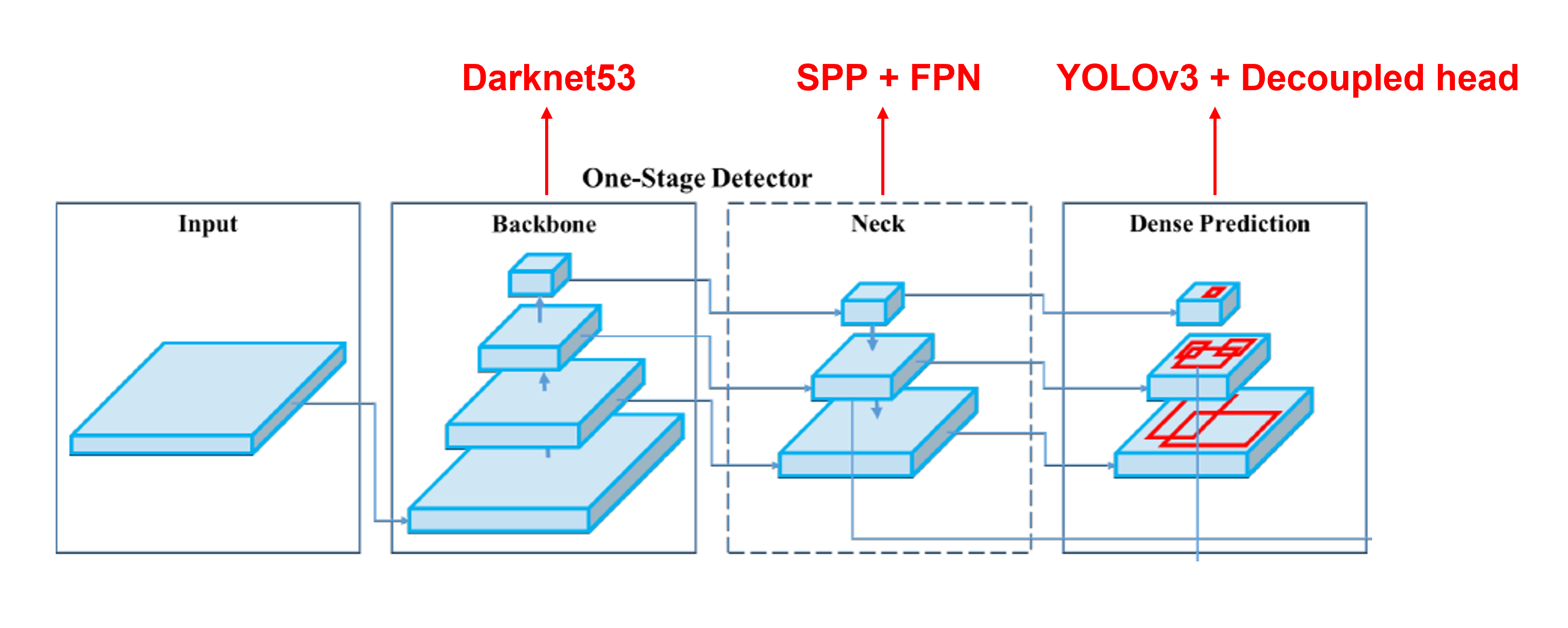
- Shared networks like Darknet (used in older YOLO versions) or CSPDarknet (used in newer models) serve as backbones to feed the network with raw data to be further processed.
- The feature maps obtained here are related to object shapes, sizes, and spatial locations.
2. Neck
The neck improves and aggregates the feature maps obtained from the backbone. It is an important part of improving object detection across multiple scales.
Techniques used in this component include the Feature Pyramid Network (FPN) or PANet, which is a Path Aggregation Network.
- The neck provides better localization of small objects and enhances the performance of detection of objects of different sizes.
3. Head
The head predicts bounding boxes, class probabilities, and confidence scores for detected objects.
• Each grid cell on the feature map predicts the probabilities and bounding box coordinates (x, y, width, height), along with a confidence score and the probability distribution over possible object classes.
• The predicted bounding boxes are compared with ground truth bounding boxes using metrics like Intersection over Union (IoU) to refine predictions.
In history, object detection based on YOLO mechanism relied on anchor boxes to predict the bounding box relative to the anchor boxes themselves.
Anchor boxes are rectangular templates of shapes and sizes in advance with defined variations in a grid cell, by which the model uses to refer to detect the objects within that grid cell.
• Role of Anchor Boxes
Anchor boxes act as priors in detecting an object having various box coordinates.
• Predict offsets two shot object detection with respect two shot object detection to its anchor box dimensions within every grid cell; this way, the model is able to capture objects of varying scales and aspect ratios.
YOLOX Anchor-Free Approach:
The anchor-based approach commonly used in most object detection algorithms is discarded in the approach of YOLOX. Its anchor-free design avoids the use of predefined anchor boxes in the object detection algorithm and results in mean average precision of mAP.
The anchor-free method directly predicts bounding box coordinates and does not rely on the use of reference templates for better adaptability to a wide range of object shapes and bounding box sizes.
• This architecture reduces the computational overhead, improves small bounding box detection, and decreases false positives.
YOLOv8 Model Sizes
YOLOv8 is the more refined version in the YOLO family, and has different model sizes depending on the requirements and computational constraints. From nano to extra-large, it covers everything from resource-constrained devices to high-performance applications.
1. Nano (YOLOv8-n)
This is optimized for the edge and applications that need minimal latency.
Good for applications such as real-time object detection on mobile devices.
2. Small (YOLOv8-s):
This is a good balance of performance and computational efficiency. It's suitable for mid-range systems where there is a need for a reasonable inference speed with good accuracy.
3. Medium (YOLOv8-m):
This model can be used as a middle ground that is situated between the two extremes of speed and accuracy.
• Often used in scenarios wherein detecting multiple objects with moderately high precision is important.
4. Large (YOLOv8-l):
• Designed for High Accuracy detection tasks, in surveillance, industrial automation
• Supports detecting in complex environments with challenging object shapes.
5. Extra Large (YOLOv8-x):
• Prioritizes maximum detection performance, achieving the highest possible mean average precision map.
• Best suited for applications with abundant computational resources, such as large-scale video analytics.
Advantages of YOLO Architecture
• Efficiency: YOLO processes the entire image in one go, significantly reducing computational time.
• Accuracy: The combination of grid cells, feature pyramid networks, and advanced loss functions ensures accurate bounding box prediction.
• Scalability: Models like YOLOv8 have been designed for different types of applications, from lightweight usage to high-performance detection workloads.
• Real-Time Capability: The YOLO object detection algorithm is better than any other algorithm in the realm of real-time object detection, which is critical in applications such as autonomous vehicles and robotics.
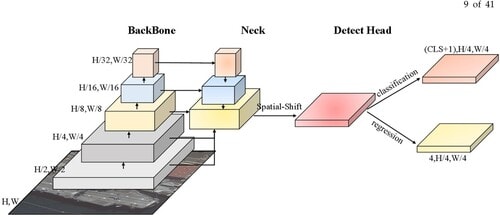
1. Backbone
The backbone is the first step of YOLOX, taking in the input image and extracting features from it. YOLOX uses a convolutional neural network (CNN), such as CSPNet (Cross-Stage Partial Network), to extract efficient and robust features.
2. Feature Pyramid Network (FPN)
The FPN combines features across the different layers of the backbone. This allows the model to detect objects at multiple scales, which means it performs better even on small bounding boxes or distant objects.
3. Detection Head
In a decoupled detection head, boxes and class probabilities are each independent branch in the detection head.
Their outputs are returned as bounding boxes together with class-specific confidence scores.
4. Grid Cells
For YOLOX, a complete image is split into cells so that every grid cell can make predictions in respect of its part of space.
Thus, it efficiently captures both the spatial as well as the semantic of information of an image.
How YOLOX Works
The object detection process in YOLOX is a streamlined pipeline:
1. Feature Extraction
The input image is forwarded through the backbone to extract meaningful features.
2. Feature Aggregation
The FPN combines features at different scales, thus enhancing the capacity of the model to handle objects of varying sizes.
3. Bounding Box Prediction
Every grid cell predicts the coordinates of two bounding boxes relative to its position, and it creates predicted boxes for all detected objects.
4. Class Probabilities and bounding box coordinates
YOLOX links with the probabilities of the pre-defined object classes, which gives a score of the likelihood of the existence of any object in that class.
5. Post-Processing
Non-Maximum Suppression eliminates the false positives and the overlapping predictions, further enriching the output.
Benefits of YOLOX
1. Real-Time Performance
YOLOX's YOLO architecture is designed to be efficient for object detection models, making it an excellent fit for applications like autonomous driving, live video analysis, and robotics.
2. High Detection Accuracy
With the aid of dynamic label assignment, multi-scale feature aggregation, and other novel techniques, YOLOX provides a high mean average precision (mAP) with fewer false positives.
3. Versatility
The model is, in fact robust for different scenarios in which the presence of small objects, complex backgrounds, object shapes, etc., can still be identified.
4. Training Ease
YOLOX is thus easier to train with minimal requirement of fine-tuning the anchor boxes and other hyper-parameters.
Comparison with other Object Detection Models
YOLOX can be compared with Two Stage Detectors such as ROI, etc.
• Speed: YOLOX's single-shot approach is faster than two-stage models like Faster R-CNN.
• Simplicity: YOLOX eliminates the need for a separate region proposal network, streamlining the detection pipeline.
YOLOX vs. Previous YOLO Versions
• Anchor-Free Design: YOLOX eliminates the dependence on anchor boxes, improving detection of irregular objects.
• Enhanced Head Design: The decoupled head improves precision in both bounding box prediction and class classification.
Applications of YOLOX
1. Autonomous Vehicles
YOLOX excels in detecting and tracking pedestrians, vehicles, and obstacles in real-time, ensuring safer navigation.
2. Surveillance Systems
The model provides accurate detection of individuals and objects, even in crowded or low-light environments.
3. Healthcare
In medical imaging, YOLOX helps detect anomalies and segment regions of interest for diagnosis and treatment planning.
4. Sports Analytics
Tracking players, balls, and equipment with YOLOX enables detailed analysis of game strategies and performance.
5. Retail and Warehousing
YOLOX supports automated inventory monitoring and checkout systems by identifying and counting items in real time.
Challenges and Solutions in YOLOX
Challenges
1. False Positives
In cluttered or ambiguous scenes, there is a possibility of wrong predictions.
2. Small Object Detection
Objects that have minimal pixel coverage are difficult to detect with high accuracy.
Solutions
1. Dynamic Label Assignment
Refines the association between predicted bounding boxes and ground truth boxes, reducing errors.
2. Multi-Scale Aggregation
Enhances the model’s ability to detect objects across multiple scales, improving accuracy for small bounding boxes.
Future Trends and Innovations
1. Integration with Edge Devices
The slim architecture of YOLOX will also make it suitable for deployment on the edge in drones, IoT cameras, and mobile systems.
2. Self-Supervised Learning
Self-supervised methods will be the basis to improve further on YOLOX performance with what deep learning research has improved on recently.
3. Novelty of Applications
YOLOX will have its applications in wildlife monitoring, augmented reality, and industrial automation, among other new applications.
In summary, what we think
YOLOX marks a new milestone in object detection, combining the best innovations of today with the proven strengths of the YOLO family.
Its anchor-free design, dynamic label assignment, and decoupled head bring forth exceptional detection accuracy and efficiency.
Whether it is about real-time applications, complex datasets, or discovering new domains in computer vision, YOLOX has the perfect balance of performance and versatility.
Having tackled the weaknesses of the previous object detection algorithms, YOLOX sets the standard for modern object detection tasks.
YOLOX presents the exciting possibility of unlocking advanced object detection methods for developers, researchers, and hobbyists and to play their part in shaping the future of intelligent systems.
Frequently asked questions (FAQs)
1. How does YOLOX differ from the conventional YOLO models?
YOLOX-a brand new state-of-the-art object detection algorithm-utilizes the advantages obtained from the YOLO family to create the most effective anchor-free method for box prediction.
It makes direct prediction of bounding box coordinates, which, compared to earlier generations of YOLO family algorithms, simplifies the whole detection process by avoiding defined anchor boxes.
It enables small objects to be detected better, and it improves computation efficiency.
2. Real Time Object Detection with YOLOX
YOLOX is entirely optimized to do real-time object detection by running the whole image in a single pass on a single convolutional neural network (CNN).
The grid cell mechanism enables for fast inference without compromising accuracy because it predicts bounding boxes and class probabilities simultaneously.
This makes YOLOX a perfect candidate for training fast, precise object detection systems for robotics, autonomous vehicles, and surveillance.
3. What are the key advantages YOLOX offers to object detection?
YOLOX brings several innovative advances to object detection models, including:
Anchor-free design: It saves a great deal of computing time by predicting directly the coordinates of the bounding boxes.
Advanced Feature Pyramid Networks, (FPN): A better approach to small bounding boxes and objects that scale at different intervals now supports better performance.
Improved Loss Function: Optimizes precision and recall to improve detection of objects to ensure YOLOX is robust in identifying objects of all shapes, sizes, and orientations.
4. What are the metrics YOLOX uses to evaluate detection accuracy and performance?
YOLOX evaluates its detection proficiency using the intersection over union (IoU) and mean average precision (mAP).
While IoU evaluates the overlap between the predicted bounding box and the ground truth bounding box, mAP assesses the model's overall precision.
5. What are the key advantages of YOLOX in object detection for AI?
YOLOX has various benefits for applications in computer vision, like:
• Efficiency: Fast detection due to its simplified architecture and optimized inference.
• Flexibility: Detects multiple objects at all scales and resolutions.
• High Precision: Predicts bounding boxes and class probabilities very accurately with low false positives.
• Versatility: Suitable for applications like image classification, real-time, object detection algorithms, and two-stage object detectors.
By combining all these strengths, YOLOX now achieves the new benchmark in object detection algorithms for AI-driven systems.