Introduction to VGG Models
Deep learning has revolutionized computer vision, where machines recognize, interpret, and process visual data with remarkable accuracy.
Among the countless architectures that have brought this success is the influence of VGG models, which are recognized as landmark milestones.
These are deep convolutional neural network architectures known for their simplicity, depth, and effectiveness in recognition tasks in images developed by the Visual Geometry Group at Oxford University: VGG16 and VGG19.
VGG models have been instrumental in achieving high performance in challenges like the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), demonstrating their value in advancing computer vision tasks.
The VGG models are a family of convolutional neural networks (CNNs) proposed by the Visual Geometry Group of Oxford University.
The idea behind these models was to enhance the performance in the execution of image recognition tasks by using deeper levels with a simple and uniform architecture of the neural networks.
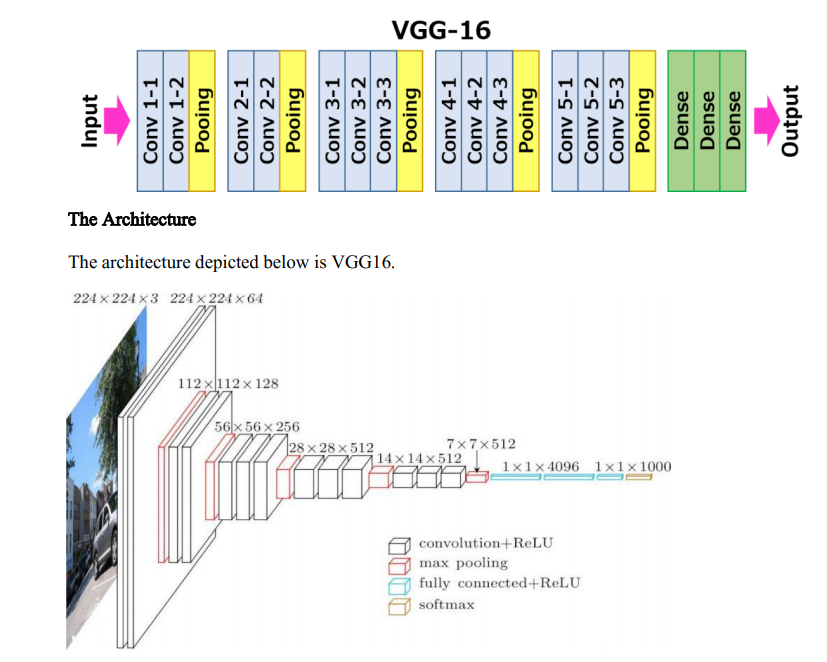
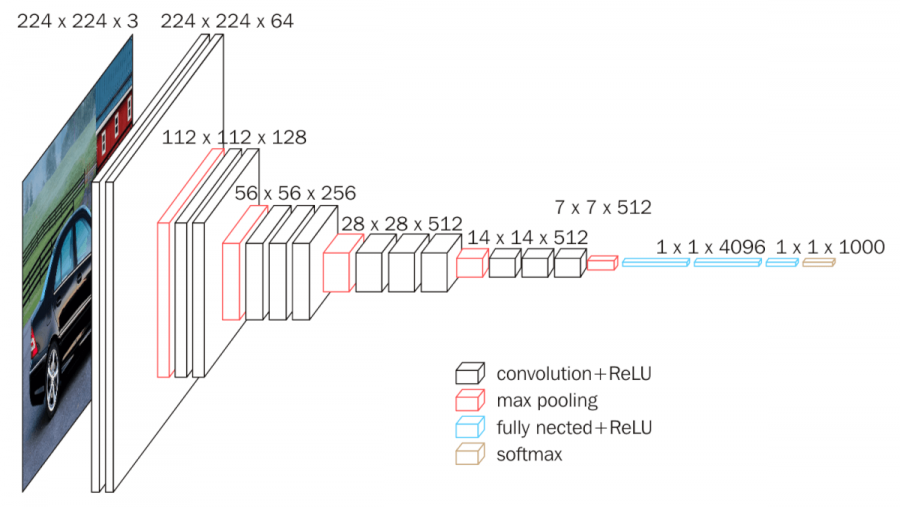
- VGG16: A CNN architecture with 16 layers: 13 convolutional layers, plus 3 fully connected (FC) layers.
- VGG19: A CNN that had 19 layers comprising 16 convolutional layers and 3 FC layers.
The success of these models was seen as state-of-the-art in the ILSVRC for their respective entry years.
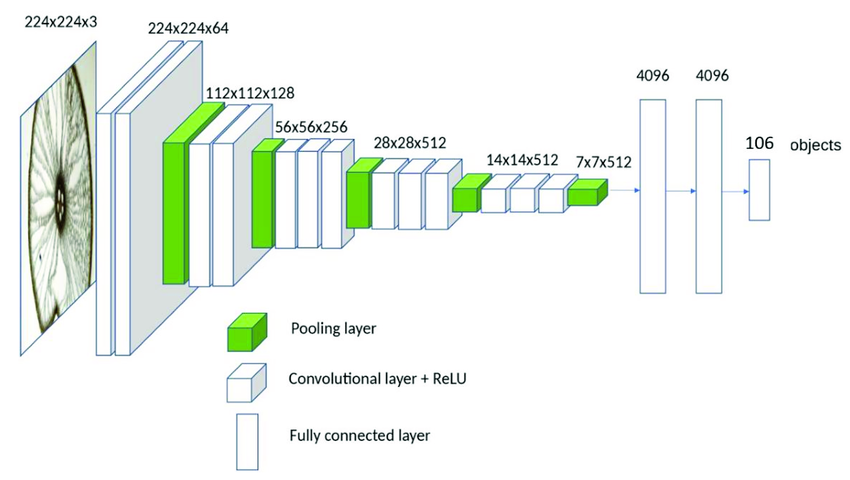
Their ability pointed toward the fact that deeper networks had the capability to provide deeper features of an image. VGG16 and VGG19, therefore became the new benchmarking measures for deep learning in computer vision.
The VGG architectures are characterized by their deep, sequential design and use of small convolutional filters.
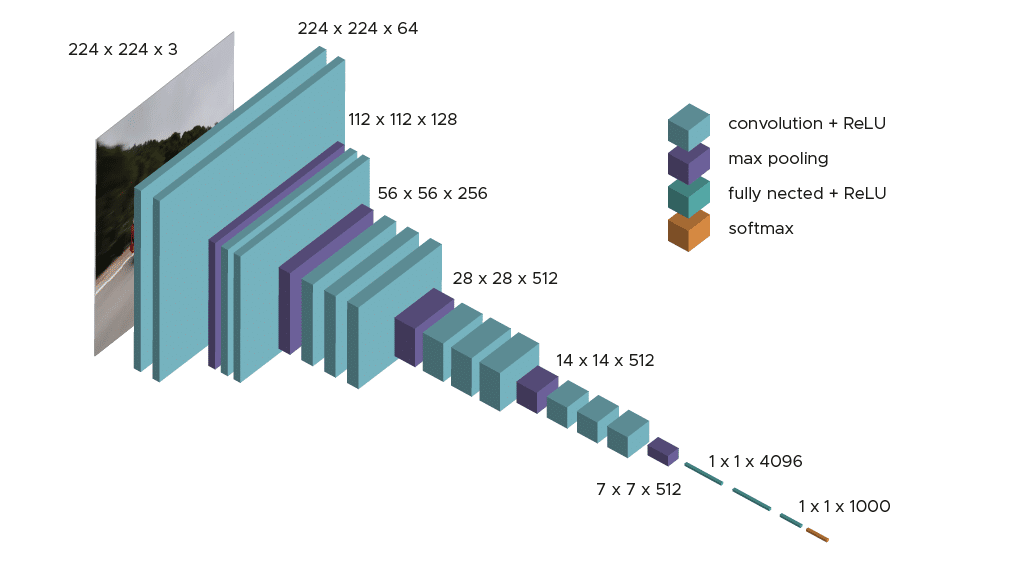
VGG16 Architecture
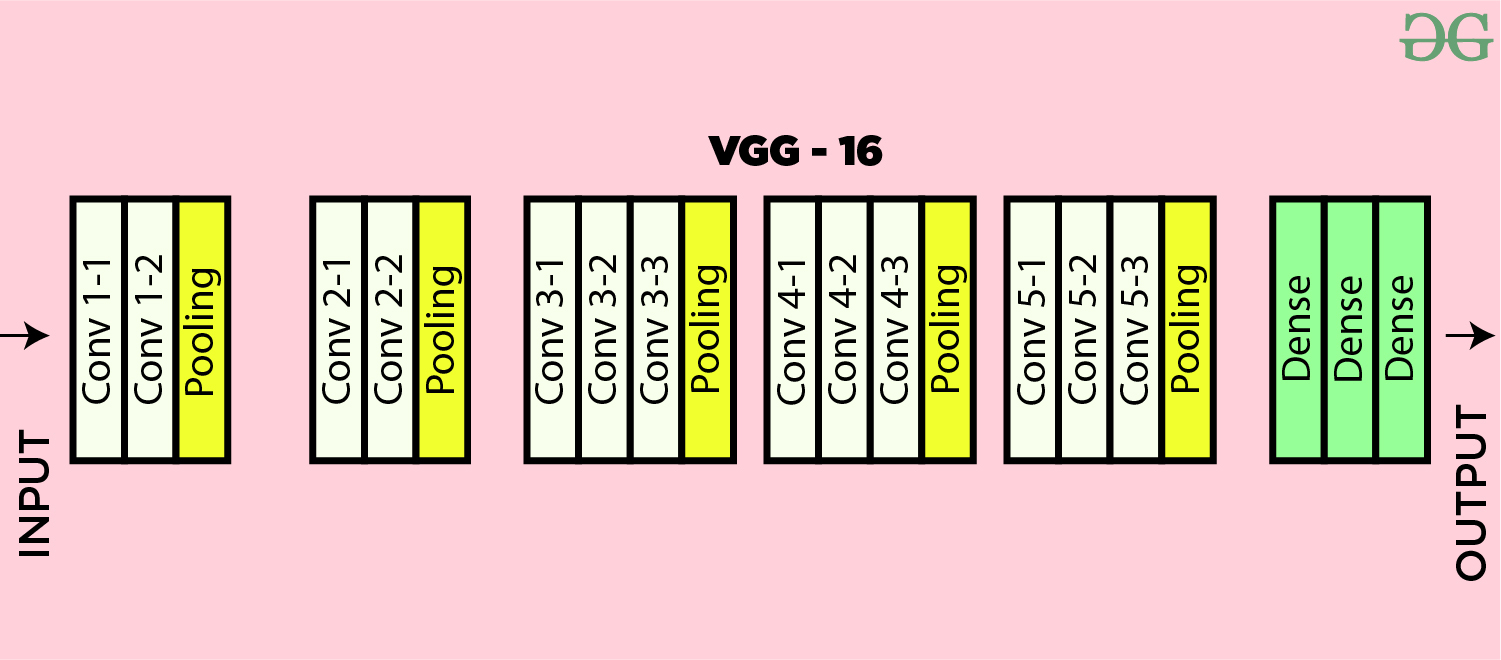
VGG16 consists of:
- 13 convolutional layers: Each applies 3x3 filters to more vigorously capture fine details and patterns.
- 3 fully connected (FC) layers: Process high-level features detected by the convolutional layers.
- Max pooling layers and re-pooling layers: Spatial dimensions of max pooling layer are reduced without affecting the important features of sequential model.
- ReLU (Rectified Linear Unit) activations: Introduced after each layer to introduce non-linearity.
That's the structure that makes VGG16 balance depth and computational efficiency, which explains why VGG16 often represents a favourite architecture in many convolution layers and feature extraction tasks.
VGG19 Architecture
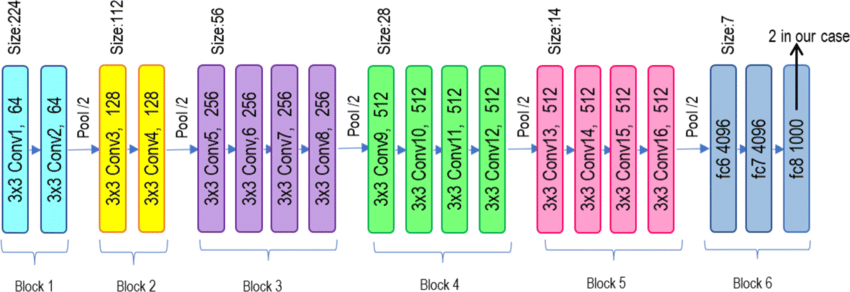
As VGG 16.19 extends upon VGG 16.16 by adding three more deep convolutional top layers with a total depth of 19 layers, it is capable of capturing more complex features, potentially at the cost of better performance in tasks requiring high granularity of features.
However, the increased depth also brings the penalty of increased computational costs, since much more computational power and memory are required due to the larger number of layers.
- Longer training and inference times: VGG19 is more computationally expensive as compared to the VGG16 model.
Despite these overheads, VGG19 is still useful where advanced feature extraction is needed.
Benefits of VGG Networks
1. Consistency in Layer Structure
The use of small 3x3 convolutional filters across all layers simplifies the architecture of the model while allowing it to learn complex patterns effectively. This consistency distinguishes VGG models from their earlier, less structured CNN predecessors.
2. Depth for Feature Extraction
Both VGG16 and VGG19 are deep networks that can recognize subtle features in an image. This makes it ideal for tasks such as three fully connected layers or convolutional neural network model, wherein picking up slight patterns is significant.
3. Transfer Learning Potential
Pretrained VGG models are now extensively used for transfer learning, where features learned on large datasets like ImageNet are fine-tuned for specific tasks. This adaptability has made the VGG models a go-to choice for developers working on custom datasets.
Limitations of VGG Models
1. High Computational and Memory Costs
VGG models require significant computational resources to train and deploy, particularly VGG19. This makes them less suitable for applications with limited hardware capabilities.
2. Parameter Intensity
With millions of parameters, VGG models are prone to overfitting, especially when used with small datasets. This necessitates techniques like data augmentation and regularization to achieve optimal performance.
3. Slower Training and Inference
VGG models are rather slow compared to more modern architectures such as ResNet and MobileNet, thus putting some practical limitations on their use in real-time applications.
Applications of VGG16 and VGG19 in Computer Vision
1. Image Classification
VGG 16-16 and the VGG 16-19 do an excellent job when it comes to the classification of images into pre-defined classes. They have been used for medical imaging to classify diseases as well as in wildlife monitoring to classify species of animals.
2. Object Detection
On using VGG models as feature extractors in the Faster R-CNN frameworks, objects have been identified in images with their locations.
3. Image Segmentation
For tasks such as autonomous driving and medical imaging, for instance, VGG has adapted their use in segmentation to divide images into meaningful regions that can later be analyzed.
4. Transfer Learning in Various Domains
Pretrained VGG models are fine-tuned for tasks like:
- Facial recognition: Identifying individuals in security systems.
- Wildlife classification: Monitoring biodiversity in ecological studies.
- Custom applications: Utilizing the powerful feature extraction capability of VGG in other domains.
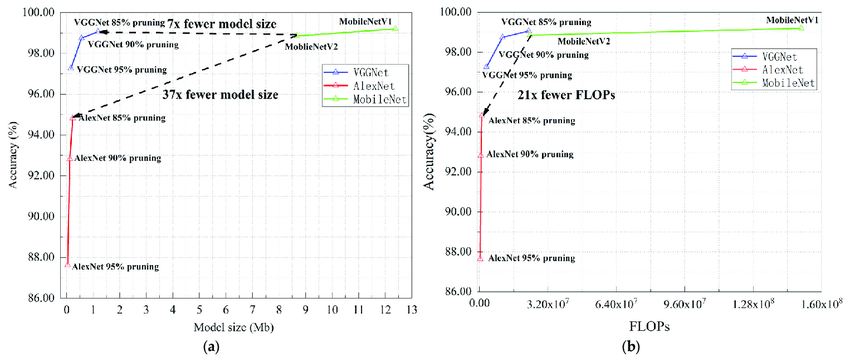
VGG16 and VGG19 compared with Recent CNN Architectures
Despite the pioneering work of VGG in deep learning in the field of computer vision, newer architectures now overcome some of its limitations.
1. ResNet and EfficientNet
- ResNet (Residual Networks): Provided residual connections to avoid the vanishing gradients problem, so networks can be a lot deeper without sacrificing the performance.
- EfficientNet: Optimized for computationally efficient by combining depth, width, and resolution, achieving high performance with fewer parameters.
2. MobileNet
- For mobile and edge devices, MobileNet applies depthwise separable convolutions that are less computational-intensive than VGG by nature.
- Even though VGG models have become less in use in production today, they remain crucial in the evolution of CNN architectures.
Future of VGG and Similar Architectures in AI
1. VGG's Legacy
The simplicity and the effectiveness of VGG models were highly inspiring to develop more advanced architectures, thus imposing their design principles on small filters and sequential depth for modern CNNs.
2. Trends in Computer Vision
Today, the direction is toward more efficient and scalable architectures that balance performance with resource constrains. Examples include lightweight models for mobile and explainable AI (XAI) for more transparency.
3. Lending Long-Term Value to VGG Models
Even though original VGG model is no longer the latest model or cutting-edge, there is value in using it to understand the basics of CNNs and as a baseline for evaluating newer models.

In summary, what we think
The VGG16 and VGG19 models were a kind of milestone within the development process of deep learning for import data stored.
Their deep, consistent architectures have established benchmarks in tasks such as: image recognition and classification, very deep convolutional networks, and image segmentation.
Despite their under-performance in computational efficiency, VGG models are still relevant for convolution layer and educational purposes.
In fact, by exploring their applications and comparing them with state-of-the-art architectures, we get an idea of the outstanding progress and potential of deep learning in computer vision models.
Frequently asked questions (FAQs)
1. What are VGG models in computer vision?
VGG models are deep convolutional neural networks that are used for image classification and feature extraction in the computer vision field. They were developed by researchers at Oxford University, and indeed, the VGG16 and VGG19 models have a very simple architecture.
2. What is the difference between VGG16 and VGG19?
The major distinction is the number of layers:
- VGG16 has 16 layers with learnable parameters (13 convolutional layers and 3 fully connected layers).
- VGG19 has 19 layers (16 convolutional layers and 3 fully connected layers).
Although VGG19 is slightly deeper, the difference is that both models are basically based on the same architecture principles, and a choice will typically depend on the application requirements or computational constraints.
3. Why are VGG models significant to computer vision?
VGG models were pioneering in demonstrating the ability of increasing depth with small convolutional filters to greatly enhance the performance of image classification tasks. They have often been utilized for:
• Image classification
• Object detection and segmentation
• Feature extraction for a few convolution layers
Their simplicity and effectiveness make them well-suited for learning the principles of deep learning and adapting to custom datasets.
4. What are the key limitations of VGG models?
The primary limitations include:
- High computational cost: VGG models require massive amounts of computational power and memory, which can make it difficult to deploy on resource-limited devices.
- Large model size: The large number of parameters increases the risk of overfitting and demands significant storage space.
- Outdated compared to modern architectures: Newer models like ResNet and Efficient. Net outperform VGG in accuracy and efficiency.
5. How are VGG models used in transfer learning?
VGG models are employed as feature extractors in large scale image recognition since their weights are pre-trained on large datasets such as ImageNet.
In this way, freezing the convolutional layers of a pre-trained VGG model enables the use of its learned features to train a classifier for specific tasks. It saves time and resources involved in its applications with limited training data.