In computer vision, object detection is a crucial task that enables machines to understand and engage with visual data.
From self-driving cars to medical image analysis, object detection models form the backbone of many applications in modern times.
Among all these algorithms, the YOLO family of models is recognized as one of the first and most efficient families within the real-time object detection boundaries.
So, the latest model from that family, YOLOv7, marks an advanced step in terms of achieving speed and accuracy in object detection.
This article explores the architecture, functionality, and advancements of YOLOv7, focusing on its state-of-the-art performance, how it compares to previous YOLO versions, and its impact on various object detection tasks.
The Evolution of YOLO: From YOLOv1 to YOLOv7
This can do two shot object detection in just one step since other object detection algorithms normally function like it.
The YOLO version does not separate proposal generation and image classification models, in opposition to two-shot methods as it uses a technique termed single shot object detection that brings about the capability for fast performance in real time with single shot object detection and detectors.
YOLOv7 develops on this momentum, bringing improvements to tackle the problems of detecting small objects, handling different aspect ratios, and getting a better detection accuracy.
YOLOv7 innovates over the earlier versions of YOLO by offering newness in the architecture of networks and training approaches that makes object detection problems better.
Overview of YOLOv7
YOLOv7 is a very strong object detection algorithm designed to thrive in many object detection tasks.
It does this by using a single convolutional neural network that predicts bounding boxes, as well as class probabilities and object locations in an image input.
The network makes these predictions on the entire image in one pass, thereby making YOLOv7 the most efficient algorithm for applying real-time object detection.
1. Improved Network Structure
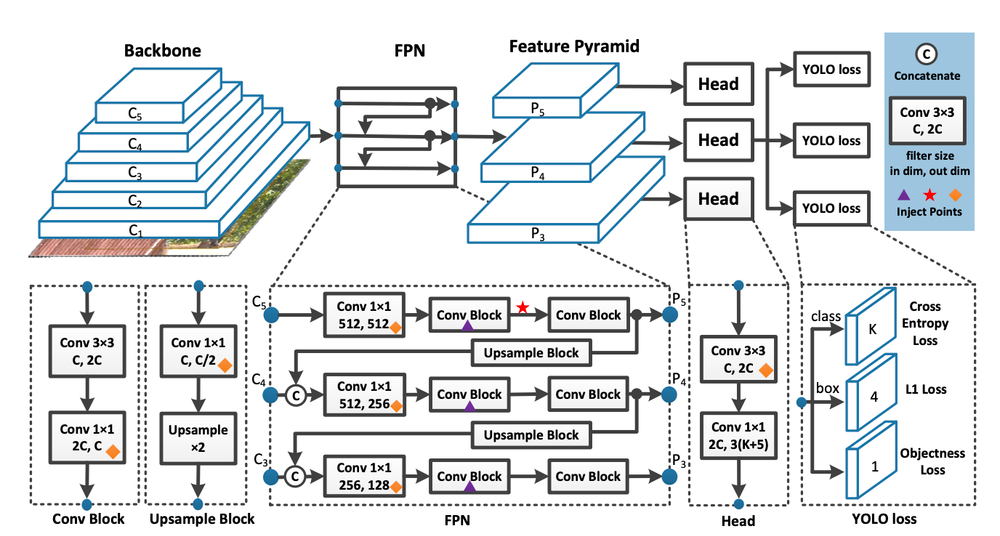
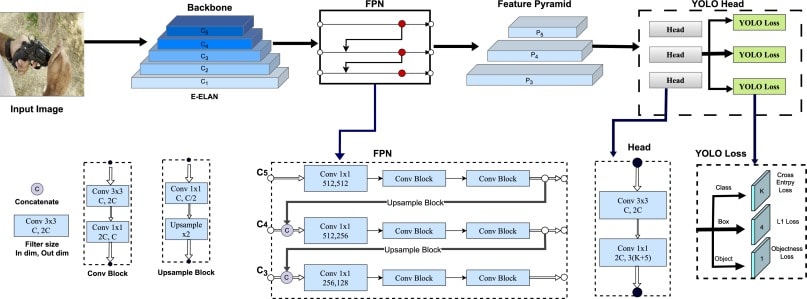
YOLOv7 employs advanced structures, such as the Feature Pyramid Network (FPN), to improve on the handling of object forms and multiple scales.
This enhances YOLOv7's capability to detect large and small objects with ease.
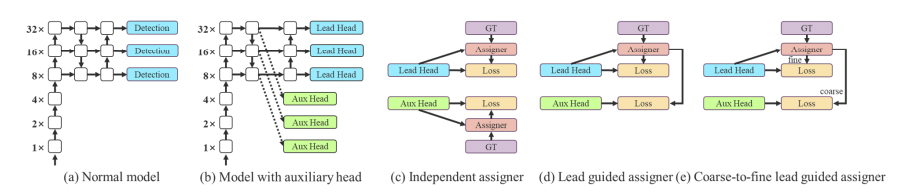
2. YOLOv7 Trainable Sack
This enables YOLOv7 to dynamically adjust its training process so that the detection limit is enhanced and the model becomes more efficient in general.
3. Edge Device Support
YOLOv7 is very efficient on NPUs with optimal model parameters, thus very well deployable on the edge devices with minimal computation powers.
4. Better Predictions for Bounding Boxes
The bounding box coordinates predicted by YOLOv7 are fine-tuned, such that the predicted bounding box coordinates would have minimal deviations from the actual bounding boxes of ground truth.
Thus, less errors would be made while detecting the objects.
The Object Detection Process with YOLOv7
The object detection process in YOLOv7 is divided into the following steps:
1. Input Image
The algorithm divides the input Images into a grid of cells. Each grid cell predicts the presence of objects and their respective bounding boxes and class probabilities.
2. Feature Extraction
Using a deep learning backbone, such as a convolutional neural network, YOLOv7 extracts relevant features from the image. This step ensures that objects of varying shapes and sizes are accounted for.
3. Predicting Bounding Boxes
For each detected object, YOLOv7 predicts the bounding box coordinates, including the box's center, width, and height. These predictions are compared to ground truth bounding boxes to calculate average precision (AP).
4. Final Output
After applying a detection threshold, YOLOv7 outputs a list of detected objects, each with a bounding box, class label, and confidence score.
Key Advancements in YOLOv7
YOLOv7 brings several improvements to the table.
1. Higher Accuracy and Inference
Speed Using a new, refined network architecture, YOLOv7 achieves higher accuracy with a balance that does not lose speed. This makes it one of the top real-time object detectors.
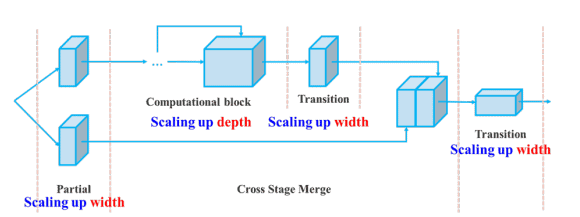
2. Compound Scaling Method
The compound scaling method allows YOLOv7 to scale its architecture to accommodate larger models while still performing well on object detection tasks.
3. Improved Detection of Small Objects
Advanced features such as anchor boxes and multiple scales enable YOLOv7 to outperform other object detectors in the detection of small objects with high precision.
4. Edge and Embedded Systems Support
YOLOv7's lightweight design allows it to run efficiently on edge devices, making it ideal for applications like self-driving cars and mobile systems.
YOLOv7 Architecture: A Comprehensive Structure
The new invention in the YOLO family, YOLOv7, has revolutionized the object detection models with a powerful and efficient architecture.
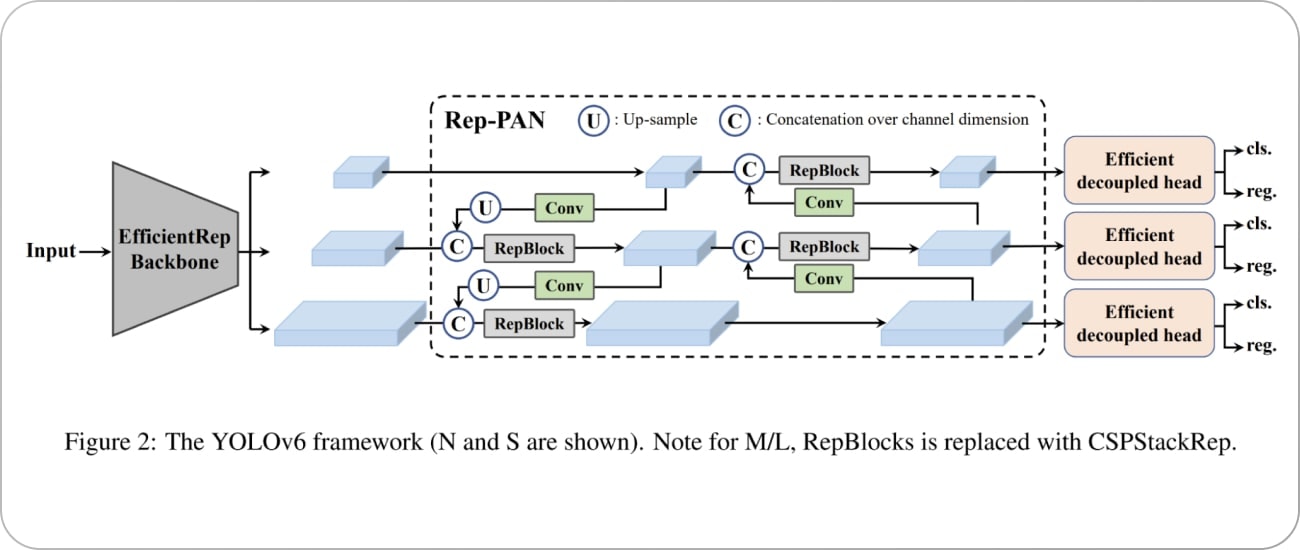
Being designed as a modular framework that comprises the backbone, neck, and head, YOLOv7 offers amazing advancements in real-time object detection and object detection tasks.
Its sophisticated design has balanced speed and accuracy, making it one of the most powerful object detection algorithms in computer vision research.
The main body of the article contains deep information on YOLOv7 architecture concerning its elements, innovation focus, and the performance achievements compared to previous versions.
Overview of YOLOv7 Architecture
The YOLOv7 architecture is a standard YOLO design that uses one convolutional neural network (CNN) to perform object detection all of objects on an entire image in one step.
It makes improvements over earlier versions to better extract features and optimize the process of object detection for improving performance on object detection problems, such as the object detection problem of small objects and managing different aspect ratios.
Key Features of YOLOv7:
• Backbone: Features are extracted from the input image using deep neural networks.
• Neck: Aggregates features coming from multiple levels of the network, thus enabling multi-scale detection.
• Head: Outputs bounding boxes and class probabilities, class probabilities, and final predictions.
Yolov7 is also integrated with the latest object detection algorithms that boost inference speed and higher object detection model accuracy.
Also, it is efficiency for deployment on edge devices and high-demand applications including self-driving cars and also medical image analysis and so on.
Key Components of YOLOv7 Architecture.
1. Backbone: Feature Extraction
The backbone is the backbone of the YOLOv7 architecture. It takes the input image and extracts the necessary features for the object detection task.
Key Features of the Backbone:
• Convolutional Neural Networks (CNNs): YOLOv7 uses optimized CNNs to extract spatial and semantic information.
• Compound Scaling Method: It further improves the efficiency of the backbone by balancing the depth, width, and resolution of the network.
• Feature Pyramid Network (FPN): This also aids the backbone to detect objects at multi-scales. As such, it is used perfectly to detect small objects.
It must ensure that, while object shapes and sizes as well as aspect ratios change with object changes, the backbone continues to keep features preserved; however, for high average precision of detection of objects in difficult scenes, this becomes a critical consideration.
2. Neck: Feature Aggregation
The neck is a middle layer connecting the backbone and the head.
The neck aggregates features from different scales and resolutions to provide the head with high resolution information to make predictions.
Key Innovations in the Neck:
• Multi-Scale Detection: The proposed method achieves robust performance in various object detection problems, such as those of varying aspect ratios and overlapping objects.
• Feature Fusion: Combines features from shallow and deep layers, ensuring a more comprehensive understanding of the input image.
• YOLOv7 Trainable Bag: Optimizes feature aggregation to improve the detection threshold for challenging objects.
The neck's ability to integrate features across multiple scales is particularly beneficial in real-time object detectors, where speed and accuracy are paramount.
3. Head: Prediction and Detection
The head of the YOLOv7 architecture will make final predictions for powerful object detection algorithm. It produces:
• Bounding Box Coordinates: The location of anchor boxes of the objects in the image is defined.
• Class Probabilities: It gives a score for each class as to which class is detected.
• Final Output: It brings the above information together into a list of detected objects with their respective bounding boxes and class probabilities.
The head is used to analyze the aggregated features into bounding boxes and predicted bounding boxes for comparing ground truth bounding boxes in order to compute average precision.
Important Head Features
• Grid Cell Approach: It divides the entire image into cells for making predictions at localized areas.
• Anchor Boxes: It improves object detection of different aspect ratios.
• Improved Optimisation: Optimises detection to achieve accuracy levels and improved speed with accuracy.
YOLOv7 Innovations
1. Improved Network Structure
YOLOv7 simplifies the network architecture to balance speed and accuracy better.
In feature extraction and multi-scale detection, it surpasses known object detectors SSD and Faster R-CNN in achieving state-of-the-art on the benchmarks of the COCO dataset.
2. Small and Overlapping Object Detection
By leveraging anchor boxes and multi-scale feature aggregation, YOLOv7 excels at detecting small objects and managing complex scenes with overlapping entities.
This is particularly useful in domains like medical image analysis and self-driving cars, where precision is crucial.
3. Optimized for Edge Devices
With fewer model parameters and efficient computations, YOLOv7 is especially apt for edge devices and low-power systems.
Its performance at such a high level of operating on a device with limited computational resources puts it at the top among real-time object detectors.
4. Enhanced Training Approach
YOLOv7 leverages state of the art top-of-the-art techniques in training, such as:
• Compound Scaling Method: It balances model complexity to enhance both inference speed and accuracy.
• Trainable Bag: The deep learning the process of the network adjusts it to better performance on the test data used for test purposes.
These techniques allow YOLOv7 to accomplish leading performance in object detection-related tasks but not necessarily robustness to variations over different datasets and conditions.
YOLOv7 vs. Past Versions of YOLO
Against past versions, especially including YOLOv5, and YOLOv4, YOLOv7 provides massive enhancements
• Speed:
The faster inference times make it much more efficient for applications requiring real-time processing.
• Accuracy:
It has architectural refinements that help improve the detection of small and occluded objects, achieving higher average precision.
- Flexibility:
It is very adaptable to different types of object detection methods, including single shot, object detection methods and instance segmentation.
YOLOv7 surpasses the rest in the performance of the MS COCO dataset. Hence, it is one among the best object detection models.
Deployment of YOLOv7
1. Self-Driving Cars: Real-time Pedestrian, Vehicle, and Sign Detection for Safe Navigation
2. Medical Image Analysis: Anomaly like Tumors Detection. Since it is highly accurate in locating objects and finding small objects.
3. Surveillance and Retail: Monitor and track inventory effectively with accurate object locations.
YOLOv7 in Action
Applications of YOLOv7
1. Self-Driving Cars
YOLOv7 enables vehicles to identify objects like pedestrians, vehicles, and road signs in real time.
Its ability to handle different aspect ratios and locate objects accurately makes it invaluable for autonomous navigation.
2. Medical Image Analysis
In medical applications, YOLOv7 is a means of object detection, like tumours or anomalies within a diagnosis image.
Its prediction on bounding box along with class probability ensures the accurate localizing of critical regions.
3. Retail and Surveillance
The system is widely used for monitoring inventories in retail. Surveillance systems also use this technique to track individuals and objects.
Performance Benchmarks
Trained on datasets such as the MS COCO dataset, YOLOv7 is achieving excellent results in terms of average precision and inference speed.
Its ability to outperform other object detectors on benchmarks like detecting small objects makes it a top contender in the field of computer vision research.
While the previous versions like YOLOv3 and YOLOv4 have already paved the way to real-time object detection, there is a great leap that comes with YOLOv7: speedier inference, and this has to do with low-latency applications, as well as precision in real time object detection that will be better than in YOLOv3 or YOLOv4 in complex scenes.
YOLOv7’s architecture adapts well to various object detection problems, from large-scale scenes to detecting minute details.
Training and Fine-Tuning YOLOv7
To achieve optimal performance, YOLOv7 requires training on labeled datasets like the COCO dataset. During the training process:
1. Input Features
The image path and bounding box coordinates are fed into the model.
2. Model Training
YOLOv7 adjusts its model parameters to minimize errors between predicted and ground truth bounding boxes.
3. Fine-Tuning
After initial training, fine-tuning allows the model to adapt to specific tasks, such as medical image analysis or surveillance.
Challenges and Future Directions
YOLOv7 sets a new high score in real-time object detection but challenges persist within enhancing performance for instance segmentation and addressing complex environment.
Computer vision research works today focus on fine-tuning these object detection algorithms to make them more efficient within different aspect ratios and conditions of occlusions.
In future versions of YOLO, these advances in the fields of neural networks, compound scaling methods, and neural processing units will be utilized in order to push the limit of performance.
In summary, what we think
YOLOv7 stands as a testament to the rapid advancements in object detection technology.
Its innovative architecture, which leverages advanced features like model scaling and real-time processing, makes it a standout solution for tasks requiring high accuracy and efficiency.
The benefits of YOLOv7 extend across diverse industries, from healthcare and retail to autonomous vehicles and security, where its applications have proven transformative.
As a leading name in AI-driven solutions, ThinkingStack embraces YOLOv7's potential to revolutionize workflows and enhance decision-making through precise object detection.
This technology exemplifies how far we've come in empowering industries with cutting-edge tools.
We encourage readers to explore YOLOv7's implementations and experiment with its pre-trained models to unlock its full potential.
By embracing tools like YOLOv7, businesses and researchers can remain at the forefront of innovation and ensure a competitive edge in an increasingly AI-driven world.