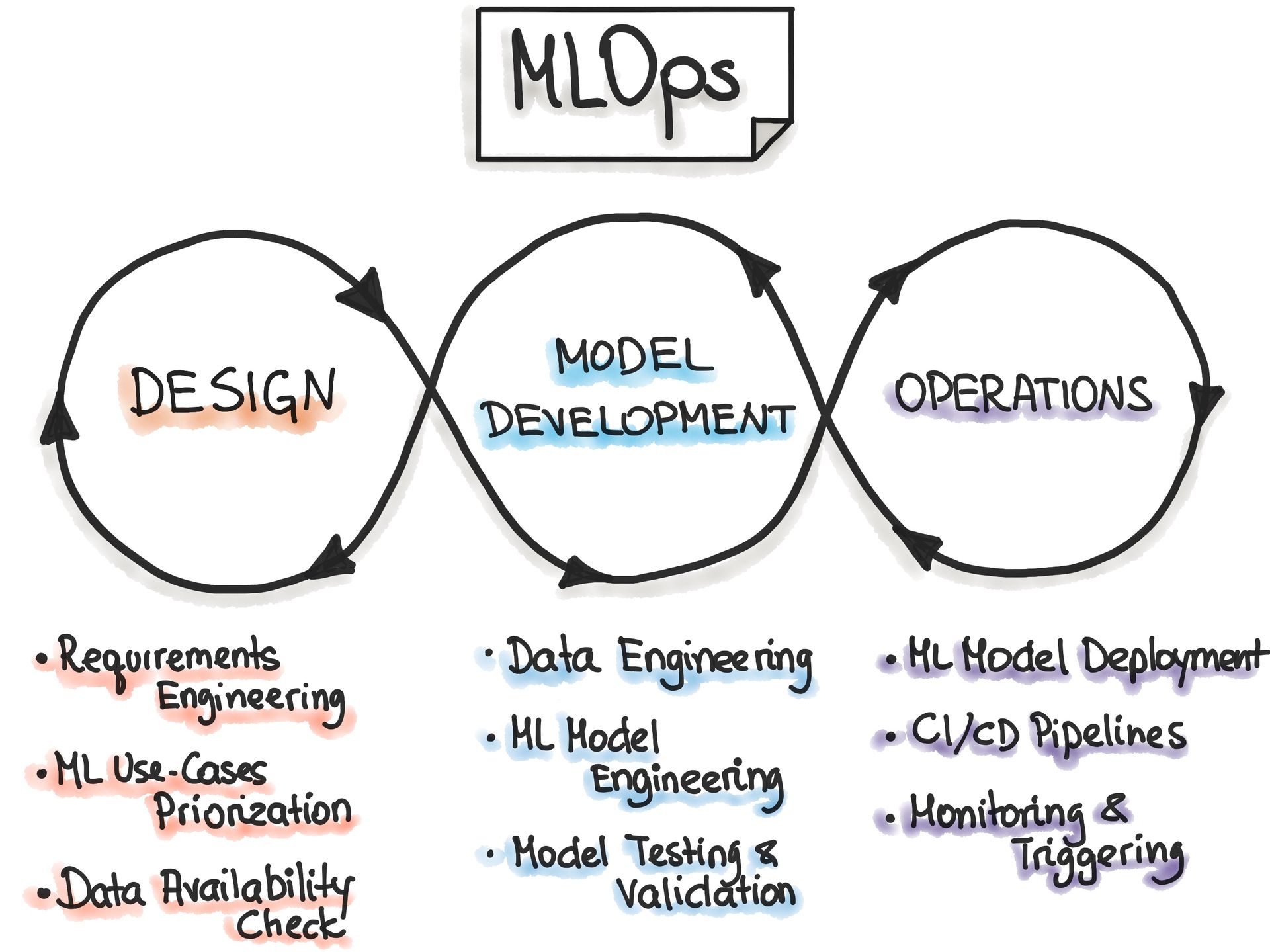
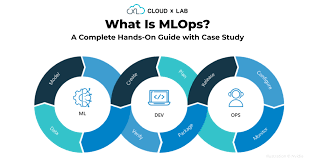
Introduction to MLOps and Scalability
What is MLOPs ?
MLOps, in other words, machine learning operations, is the chief most imperative constituent that deals with deploying machine learning models into the production environment.
This development or, in another sense, Dev and Ops portmanteau enables the smooth running of machine learning models by introducing software engineering into data science.
Also, MLOps refers to the practice of integrating machine learning model development with software engineering and operational processes.
It allows the efficient deployment, monitoring, and management of machine learning models in production environments.
This technology is expected to smoothen all steps in a machine learning lifecycle that involves data collection, model training, model deployment, and continuous model monitoring.
The main reasons why organizations adopt MLOps are its capabilities for workflow automation, quality control of a model, frequent model versioning, and enabling
data scientists and ML engineers to work together more effectively. It is similar to DevOps but for machine learning: how models are built, trained and validated model then scaled and maintained in production efficiently.
How does it work?
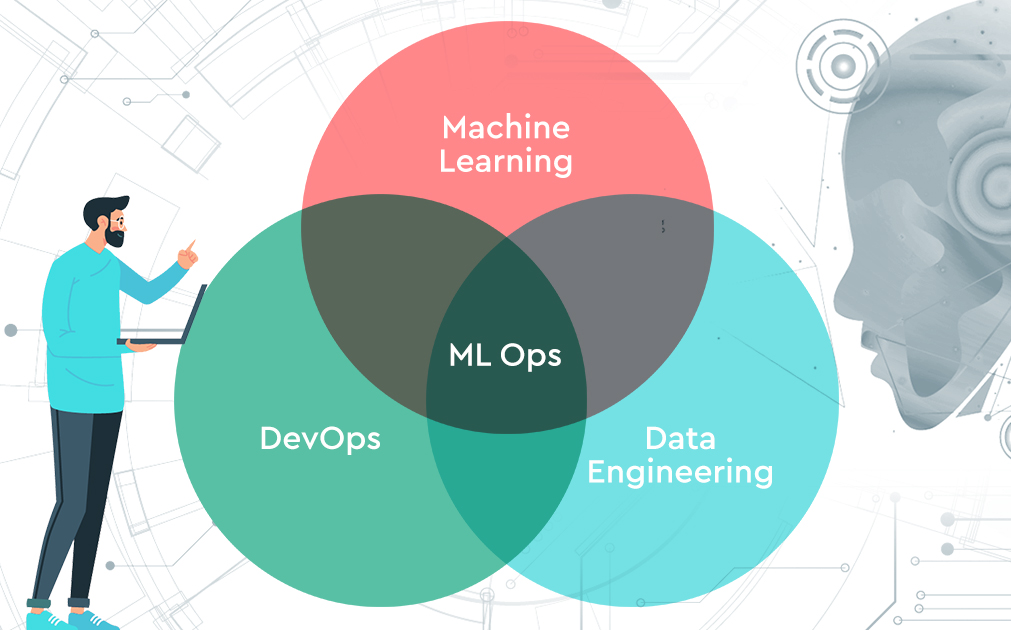
MLOps tries to bridge the gap between model development and deployment, allowing data scientists and machine learning engineers to drive better collaboration.
One of the major issues that a practitioner would face in MLOps is scalability, which needs to be considered in machine learning systems so that they are able to process volumes of continuously growing data, model complexity, and production needs without degradation in performance.
MLOps scalability is quite crucial when dealing with large-scale ML models, such as deep learning architecture where model training and inference processes are very computation-heavy.
Large models are very challenging to deploy and maintain efficiently.
The article will review the importance of scalability in MLOps, challenges related to scaling ML models, and strategies to make the machine learning workflow robust.
Understanding Scalability in the Context of MLOps platform
Scalability in Machine Learning and MLOps defined:
In the context of machine learning, scalability generally means being able to process greater volumes of data, being able to use larger models, or deploying models more often without a hit on model performance.
Model performance
It ensures that an ML system can grow either by volume of data, by model complexity, or users in a very efficient and sustainable manner.
Types of Scalability: Horizontal vs Vertical Scaling
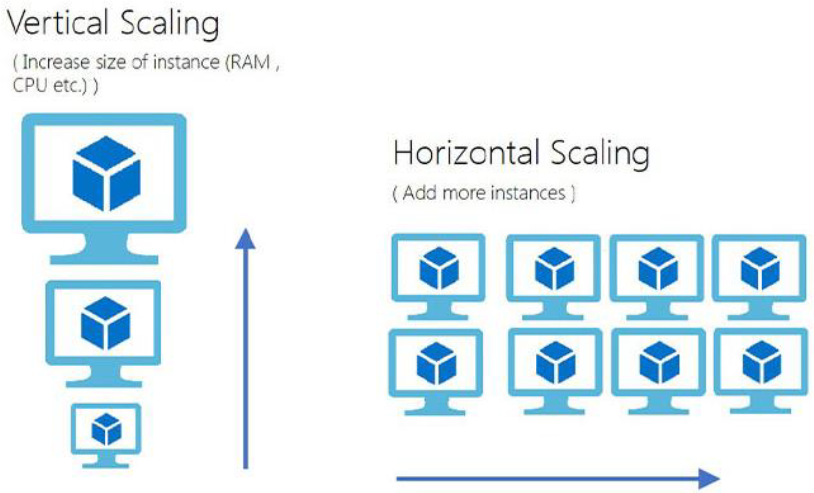
Horizontal Scaling:
It means addition of more machines or nodes to distribute the workload between multiple systems.
Quite a common approach in cloud environments, horizontal scaling provides dynamic resource allocation based on demand.
Vertical Scaling:
This is about increasing the capacity of one machine, either by putting more memory or making it more powerful.
Vertical scaling is more amenable to single-machine operations but may fall short beyond a certain level of scaling.
Key Scalability Metrics: ML Models
1. Throughput:
The number of data processed during model training data analysis and inference.
2. Latency:
Time taken by a system to react to something requested-for example, a model making a prediction.
3. Model Performance:
Accuracy, precision, recall, and other evaluation metrics that define how well ML models are doing.
4. Resource Utilization:
Judicious use of hardware resources such as CPUs, GPUs, and TPUs for the performance of models.
Scaling Challenges of Large-Scale Machine Learning Models in production environment

Data Management Challenges:
With larger models, the amount of data for training and inference grows exponentially.
Large datasets have to be collected, preprocessed, and stored; that becomes quite resource-consuming.
Handling both the structured data and unstructured data in huge volumes requires substantial pipes for ensuring data validation, feature engineering, and data transformation.
Computational Resource Challenges:
Scalability of machine learning models uses all forms of computation involving CPUs, GPUs, and TPUs.
In many cases, one has to resort to distributed computing for large model training-like GPT or BERT.
This management ensures that training and inferences can be cost-effective.
Model Complexity:
While there are models featuring millions of parameters, special hardware and software frameworks put these complex models into work.
Though deeper architectures like CNNs or transformers can be computationally expensive, their scalability leverages efficient parallel processing.
Real-time Deployment:
Real-time model predictions call for low latency and high availability, which becomes even more crucial in production environments when the deployed model prediction service needs to respond immediately.
Ensuring scalability here is crucial for many applications that range from recommendation engines and fraud detection systems to voice assistants.
Cost Considerations:
While scaling large models involves very high infrastructure costs, optimization of cloud infrastructure or on-premise systems can bring down the expense.
However, trade-offs between performance and cost have to be carefully managed.
Scalable Data Pipelines in MLOps platform
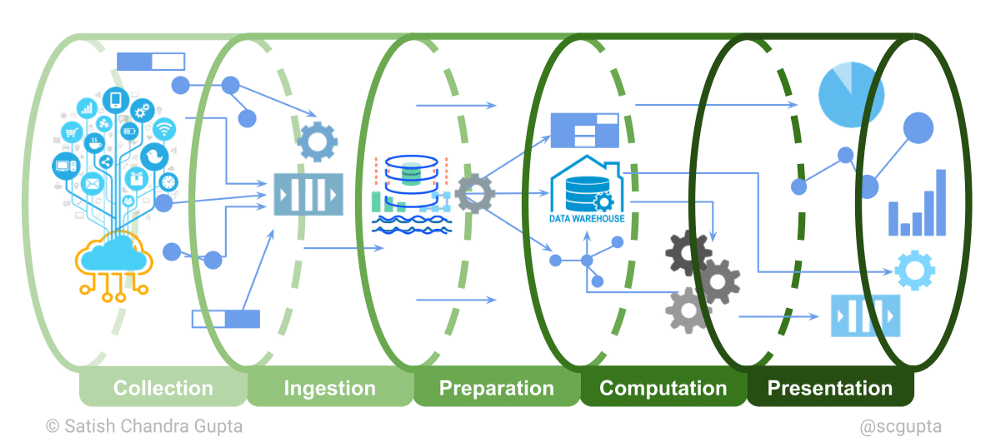
First, there is a need for a scalable data pipeline for training and inference.
Efficient pipelines are necessary to manage data collection, preparation, validation, and transformation by data science teams.
As the volume of data increases, these pipelines keep the efficiency of model training and inference intact.
Scalable Data Pipelines: Tools to Build
Apache Kafka:
A distributed event streaming platform that helps in managing gigantic volumes of data in real time.
Apache Spark:
Open-source, distributed computing system with high-level APIs in Java, Python, and Scala, besides providing high performance for fast processing of large datasets.
Apache Airflow:
Programmatic platform to author, schedule, and monitor workflows.
Best Practices for Data Versioning, Validation, and Transformation
Data Versioning:
Handle diverse dataset model versions together. On account of this very fact, it is a good method of achieving reproducibility and coherence in model training.
Data Validation:
Automate data validation. This exploratory data analysis should be done by testing the quality and integrity of incoming data.
Data Transformation:
Use scalable tools like Spark for processing and transforming huge volumes of data.
Scaling Infrastructure of Machine Learning Models
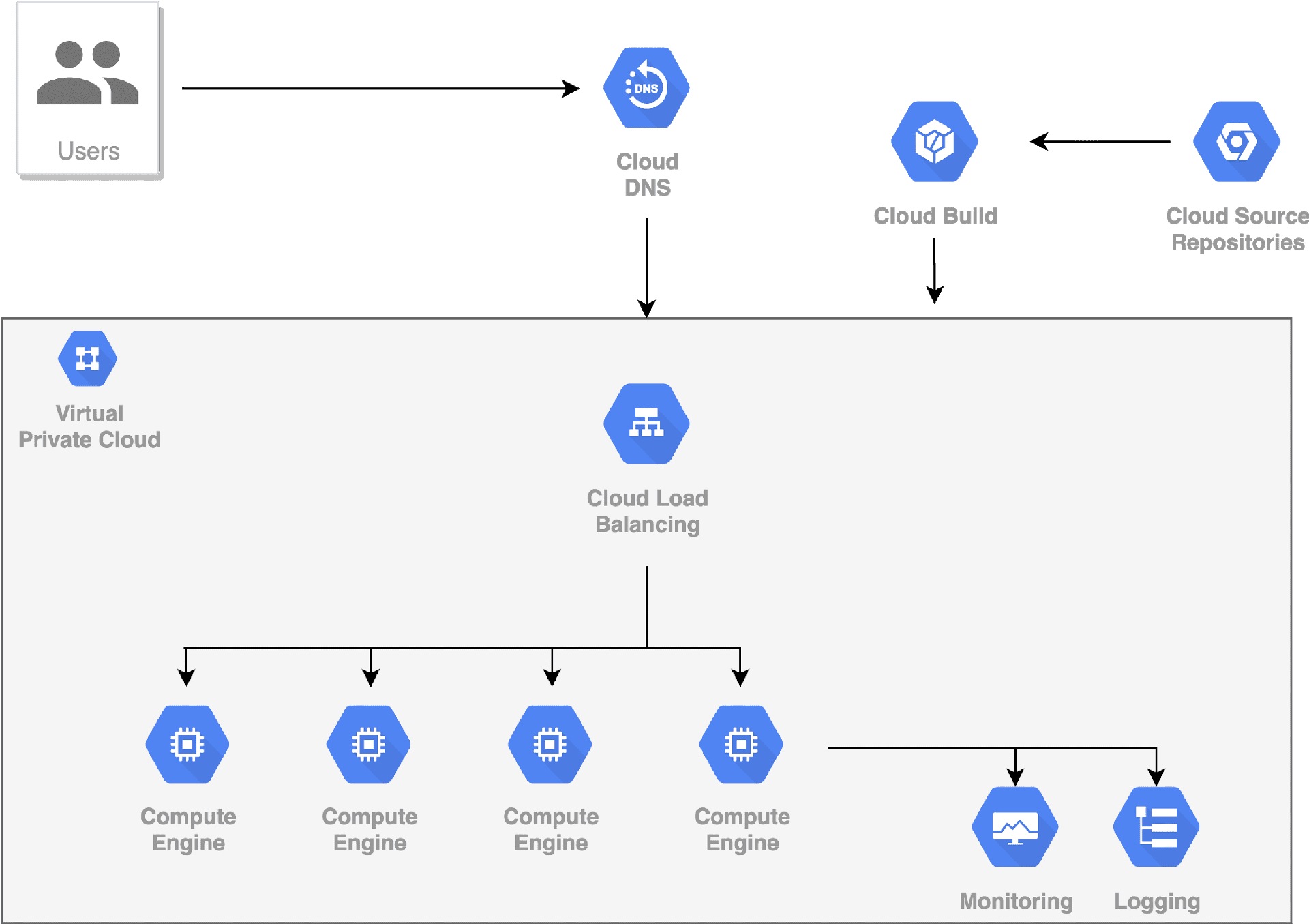
Role of Cloud Platforms:
Cloud platforms such as AWS, Azure, and GCP will play a crucial role in scaling the machine learning lifecycle.
They offer on-demand scalable computing resources that empower data science teams to train models and deploy machine learning across multiple environments.
Containerization and Microservices:
Docker and Kubernetes:
Containerization technologies allow the exposition of machine learning models in scale and with flexibility.
Kubernetes offers automation for deploying, scaling, and operating containerized applications.
Microservices Architecture:
Breaks down large-scale software systems into smaller independent services that can be individually scaled.
This is one of the approaches to enhancing scalability and flexibility.
On-Premises vs. Cloud-Based vs. Hybrid Infrastructures:
Each kind of infrastructure has its pros and cons.
While cloud-based infrastructures offer scalability and flexibility, on-premise infrastructures offer a possibility to have full control of data security and compliance.
A hybrid infrastructure leverages the best of both worlds by taking the scaling ability from the cloud for specific operations to run more sensitive operations on-premise.
Model Training at Scale
Distributed Training Techniques:
Data Parallelism:
Splits the data across multiple nodes for concurrent training of the model.
Model Parallelism:
This splits the model itself across different machines, enabling large models to be trained that could not fit into the memory of a single machine.
Pipeline Parallelism:
This breaks down the training process into stages and then distributes these across nodes in an effort to improve efficiency.
Utilizing Specialized Hardware
Hardware accelerators such as GPUs and TPUs are very important to train big models.
Both TensorFlow and PyTorch have support for distributed training across these devices to further improve the training performance of a model.
Using Distributed Training Frameworks:
TensorFlow and PyTorch:
The obvious leading frameworks offering support for distributed training.
Horovod:
A distributed deep learning training framework that can efficiently scale your training on multiple machines.
Model Deployment and Serving at Scale
Best Practices for Scalable Model Deployment:
- Canary Deployments:
First deploy the models to a small fraction of users, test the performance, and then totally deploy them.
- Blue-Green Deployments:
Prepare two environments, green and blue, in parallel. This will facilitate easier switching to another model.
- Shadow Deployments:
Deploy a model aside but without disrupting the users' traffic; the users will be directed to the newly deployed model.
Deploying Models at Scale serving:
TensorFlow: Serving is a flexible, high-performance serving system for machine learning models.
Torch Serve: Software serving PyTorch models at scale.
Kubernetes: An orchestrator for containerized applications in deploying ML models to production.
Continuous Integration and Continuous Deployment within MLOps for Scalability
CI/CD Pipelines Customized for Machine Learning:
CI/CD pipelines ensure models are deployed in a continuous processing, training, and validation cycle.
With tools such as Jenkins, GitHub Actions, and Kubeflow, data science teams can automate their workflows in the enablement of continuous delivery of machine learning models.
Automating Model Retraining and Validation:
Model retraining and validation can be automated to ensure that models stay current with the new data.
This automated pipeline would keep an eye on model performance for initiating retraining if needed.
Monitoring and Managing Large-Scale Models in Production environment
Continuous Monitoring for Model Drift and Performance:
After the model is deployed, it should be continuously observed regarding its performance to detect degradation in performance or model drift.
Tools like Prometheus, Grafana, and Datadog offer real-time insight into the model's performance and help quickly troubleshoot and optimize the model performance.
Automated Model Management:
Automated model management practices include A/B testing, rollback strategies, and model governance in efficiently managing large-scale machine learning projects.
Additionally, performance anomaly detection monitoring on ML models ensures they keep up with performance expectations.
Case Studies of Scalable MLOps Implementations
A real-world example of the case study on MLOps is the Michelangelo platform by Uber, developed in response to the need to produce and manage machine learning models in production.
Uber needed a robust system to handle creating, deploying, and monitoring a large number of ML models powering a variety of services-from ride pricing and ETA predictions to fraud detection.
Herein, Michelangelo integrates the best practices of MLOps for the automation of data preparation, model training, experiment tracking, and continuous model monitoring.
The Uber platform provides data scientists and engineers with simplicity in deploying models into production while actively monitoring their performance and ensuring newly trained models update efficiently.
It has enabled Uber to execute widespread deployments of machine learning models at scale on high volumes of real-time data for making accurate predictions and, hence, optimizing business processes throughout the organization.
A very relevant case study in scalable MLOps is the implementation of edge AI and federated learning for its Gboard keyboard app by Google.
Confronting the challenge of training predictive text models with protection of users' privacy, Google has adopted a federated learning approach whereby model training would take place directly on the users' devices rather than on some centralized servers.
Decentralization allowed scaling to millions of devices, without necessarily compromising users' privacy, since raw data was not being sent back to the cloud.
Besides federated learning, Google connected edge AI.
Allowing models to run with near-zero latency and requiring only occasional use of cloud resources.
To further scale, model optimization techniques such as quantization and pruning were applied to shrink the sizes of the models, hence operating efficiently even on resource-constrained mobile devices.
The described MLOps system would update and fine-tune the models in real time without disturbing the user experience, thus representing one of the most advanced ways of large-scale machine learning workflow management.
Similarly, several companies have scaled their machine learning operations already. These include large-scale recommendation systems, fraud detection models, and NLP systems.
This basically shows the very core of scalability in MLOps and the essential tools, techniques, and frameworks required for such scaling.
Future trends in Scalable MLOPs platform
Several emergent trends shape the future of scalable MLOps: federated learning, edge AI, and real-time MLOps.
Federated learning enables decentralized model training across a fleet of devices with no need for the raw data to be shared while enabling privacy and scalability for distributed systems.
Edge AI pushes computation to where the data source is, such as IoT devices, for less latency and better real-time decision making while taking off some demand from centralized servers.
Real-time MLOps deal with model management and deployment in dynamic environments, where the expectation for immediate response and update is high.
In addition, there are optimization methods like quantization and pruning that compress a model to smaller size than it is, hence decreasing the computation cost spent on their deployment.
Better AI infrastructure therefore also increases the scalability of machine learning models, with more powerful cloud-native tools and specialized hardware allowing better utilization of resources and flexibility in deployment.
More future trends in scalability within MLOps will be driven going forward by the increasing integration of AutoML and serverless MLOps.
Applying AutoML tools allows a data scientist to scale up the development process of models by automating tasks in feature engineering, model validation, and hyperparameter tuning that make it easier to handle large-scale workflows in machine learning.
Meanwhile, serverless architectures will finally enable machine learning engineers to deploy models without any hassle of managing infrastructure, which enables better scaling of unpredictable workloads.
In addition, multi-cloud strategies will further provide the flexibility to scale machine learning models across different cloud providers to optimize costs and performance.
These are joined by advances in AI model orchestration and an improvement in the management of infrastructure that will enable seamless scalability in machine learning pipelines within organizations.
Conclusion
Scalability is a significant factor in handling large-scale machine learning models in MLOps.
As a machine learning project grows in terms of complexity, a data science team should be focused on scalable tools, frameworks, and best practices to efficiently model, train, and deploy the models.
Through the use of distributed computing, cloud infrastructure, containerization, and continuous integration, organizations ensure that their machine learning models are performant and scalable while trying to keep costs low for production environments.
Frequently asked questions (FAQs)
1. What is the importance of scalability in MLOps?
Ans: Scalability in MLOps is crucial for ensuring that machine learning models can handle increasing data volumes, growing model complexity, and evolving production requirements.
As machine learning projects expand, scalable solutions ensure that model training, deployment, and inference can be performed efficiently across various environments.
Without scalability, performance may degrade, leading to longer training times, higher latency in predictions, and inefficient use of computational resources.
2. How do horizontal and vertical scaling differ in the context of MLOps?
Ans: - Horizontal scaling involves adding more machines or nodes to a system, distributing the workload across multiple instances.
This method is commonly used in cloud environments to scale machine learning pipelines and services without affecting individual node performance.
- Vertical scaling increases the capacity of a single machine by adding more CPU, memory, or GPU resources.
While vertical scaling improves the performance of individual machines, it has physical limitations and may not scale as effectively as horizontal scaling for large-scale models.
3. What are the main challenges of scaling machine learning models in production environments?
Ans: Key challenges include:
- Data management: Handling large volumes of training and inference data requires efficient storage, a data processing,, and validation pipelines.
- Computational resources: Scaling models often demands specialized hardware like GPUs and TPUs to handle the computational requirements of large models such as GPT or BERT.
- Model complexity: As models become more complex, the need for efficient parallelization increases, and maintaining performance in real-time deployment environments becomes difficult.
- Cost management: Scaling infrastructure can be expensive, and optimizing for both performance and cost is essential to avoid prohibitive resource expenses.
4. What are some tools used for scalable model deployment in MLOps?
Ans: Several tools are widely used for deploying models at scale:
- TensorFlow Serving: A flexible tool designed for serving TensorFlow models in production environments.
- Torch Serve: Developed for serving PyTorch models, Torch Serve provides scalable inference for deep learning models.
- Kubernetes: A container orchestration tool that automates the deployment, scaling, and management of containerized applications, making it ideal for scalable ML model deployments.
5. How does continuous integration and continuous deployment (CI/CD) enhance scalability in MLOps?
Ans: CI/CD pipelines automate the process of testing, validating, and deploying machine learning models, ensuring rapid iteration and scalability.
By integrating tools like Jenkins, Kubeflow, and GitHub Actions, data science teams can automate workflows, reduce manual intervention, and maintain consistent model performance.
CI/CD also enables frequent model version deployments, retraining on new data, and quick rollbacks if issues arise, ensuring that the machine learning lifecycle is scalable and efficient.
6. What is the role of containerization in scalable MLOps?
Answer: Containerization, using tools like Docker and Kubernetes, allows machine learning models and their dependencies to be packaged into isolated, portable environments.
This enables scalable deployments across different environments and ensures consistency in model performance.
By leveraging containers, teams can easily replicate, scale, and manage large-scale models in production without worrying about underlying infrastructure differences.
7. How does real-time MLOps differ from traditional MLOps?
Answer: Real-time MLOps focuses on deploying and managing machine learning models in dynamic environments where models must make near-instant predictions, such as in fraud detection or recommendation systems.
Unlike traditional, MLOps tools, which may handle batch processing, real-time MLOps requires constant monitoring, low-latency model inference, and rapid model updates to ensure the system can handle live data streams efficiently and accurately.
8. How does model optimization affect scalability in MLOps?
Answer: Model optimization techniques like quantization, pruning, and distillation help reduce the computational load and memory footprint of machine learning models, making them easier to scale in production.
Optimized models can handle higher data volumes and reduce inference latency, allowing them to be deployed in resource-constrained environments such as edge devices or mobile platforms while maintaining high performance.
9. What are the key differences between scaling training and scaling inference in machine learning?
Answer: Scaling training focuses on handling large datasets and distributing the model training process across multiple machines or using specialized hardware like GPUs and TPUs.
Scaling inference, on the other hand, is concerned with ensuring that a deployed model can handle real-time or high-frequency prediction requests in production.
While both involve scalability, training is more focused on processing data efficiently, whereas inference requires low-latency, high-throughput model serving.
10. How do CI/CD pipelines improve the scalability of machine learning workflows?
Answer: CI/CD (Continuous Integration/Continuous Deployment) pipelines automate the process of testing, validating, and deploying machine learning models.
By enabling frequent model versioning, retraining, and deployment, CI/CD ensures that new models are quickly moved from the development or experimentation environment into production.
This level of automation allows for greater scalability, as data science teams can manage and update models more efficiently without manual intervention, ensuring that machine learning workflows can adapt to increasing complexity and data size.
Start writing here...