Introduction to 3D Object Detection
What Does It Mean to Detect 3D Object Detection? Why is it Important in Computer Vision?
3D object detection is one of the most fundamental and challenging areas of computer vision and includes recognizing, classifying, and locating objects in space.
Unlike simple detection of 2D objects, which depends only on two-dimensional image data, 3D object detection allows machines to provide a sense of depth and spatial relationships that exist in the real world.
It is due to this reason that it is the most important feature for applications where high accuracy in navigation, interaction, and decision-making will be needed.
Applications such as autonomous vehicles, robotics, augmented reality (AR), and virtual reality (VR) come into this category.
Understanding the physical make-up of objects, such a system can then go on to interact more accurately with its surrounding environment, and 3D object detection can be considered the foundation of AI for real-world applications.
2D vs 3D Object Detection models
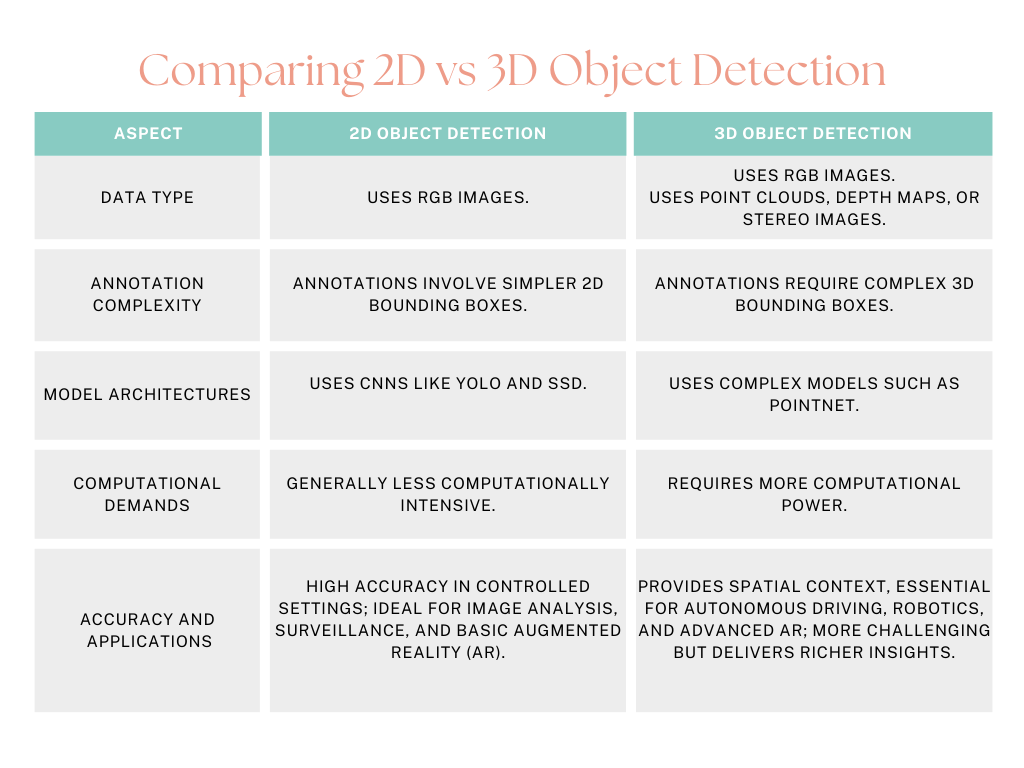
The difference between 2D and 3D object detection is the dimensionality. The 2D object detection directly works on images, extracting features such as width and height but not the depth.
It detects objects as being presented in a plane 2D and gives a bounding box for boxes in the same plane. To say it in simple words, the 3D version includes the depth dimension of the object, allowing it to detect an object in a space of three dimensions.
This makes all the difference when it comes to self-driving applications, where knowing distances between two objects are, their dimensions, and positions may directly affect decision making and safety.
Key Applications of 3D Object Detection models
1. Self-Driving:
It is vital for autonomous vehicles so that one can see real-time pedestrians, vehicles, obstacles, or road features.
It is important for navigation, collision-free avoidance, and making decisions.
2. Robotics:
To understand the environment in which they operate, robots use 3D object detection to navigate, manipulate, and interact with the environment. This is mainly true in automation tasks, management of warehouses, and robotic surgery.
3. Augmented Reality (AR) and Virtual Reality (VR):
3D object detection improves the AR and VR experience by enabling accurate interaction with virtual elements. It further makes it possible to integrate the real-world objects into virtual environments, which provides more authentic experiences.
4. Health:
Applying 3D object detection in medical image processing, abnormalities in CT scans or MRIs can be detected to increase the diagnostic accuracy and allow for more precise treatment planning.
Overview of Methods of 3D Object Detection
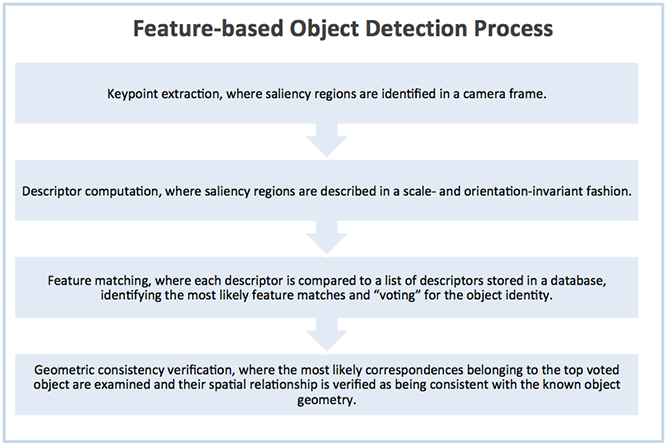
How Does 3D Object Detection Work? From Data Acquisition to Model Inference
The first step in 3D object detection is data acquisition. This is done through sensors such as LiDAR, RGB-D cameras, or stereo cameras. Such an acquisition captures 3D information, which is then transformed into representations such as point clouds, voxels, or RGB-D images, among others. These representations are fed into deep learning-based machine learning models for training and identification of objects. The trained models are then deployed for inference to either identify objects for the presence, location, or classification of objects in the scene.
Key Features
- Point Clouds:
A set of data points in space usually derived from LiDAR sensors, that indicate the outer surface of objects.
- Voxels:
A 3D cube structure for segmenting the space into tiny cubes for ease of processing using deep models.
- RGB-D Images:
A standard RGB image and depth information captured by depth cameras.
- Depth Sensing:
Approach through which the distance of objects from the sensor is obtained for understanding their position in space.
Types of 3D Object Detection Techniques
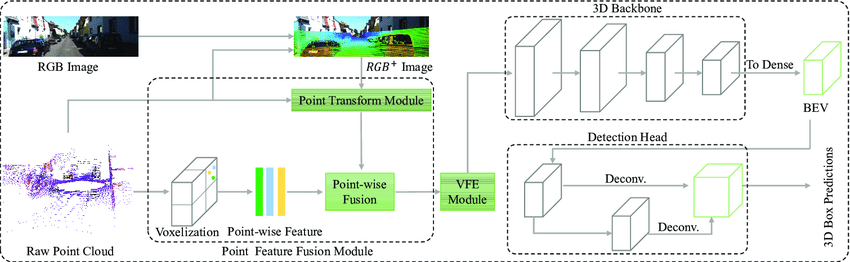
1. Point-based Techniques:
They directly process 3D point clouds that can allow fine-grained detection.
2. Voxel-based Techniques:
These transform the point clouds into voxel grids to ease the structure of data and utilize CNNs.
3. RGB-D Based Techniques:
These techniques utilize the RGB images and depth data for more accurate results.
4. Hybrid Methods:
Using more than one representation two main types of data to improve performance.
Hybrid methods exploit the strengths of the different representations in order to improve performance.
Point-Based Methods for 3D Object Detection
Point-based methods are methods that directly work on point clouds, allowing for detailed analysis of 3D scenes. Such techniques include:
• PointNet:
This is a method that processes points in parallel and aggregates them globally. This is an efficient method for sparse data because it does not update its internal state after consuming input.
• PointNet++:
A variant on top of PointNet, this method also captures the local structures of point clouds that enhance accuracy for complex scenes.
PointRCNN:
Uses region proposal networks to detect objects in the 3D point clouds with strong emphasis on high-precision detection.
Advantages
The point-based approaches are highly efficient with sparsity data, very characteristic of point clouds.
Additionally, they allow flexibility in image processing for different tasks together, and can perform accurate detection in diverse scenarios and environments where objects are complex in configuration.
Disadvantages
The main drawback is the computational intensity of point clouds processing. Besides, capturing local structures detecting objects is not straightforward on point clouds, which might be the root of low accuracy in object detection.
Recent Advances and Challenges
Voxel-Based Methods for 3D Object Detection
The voxel-based methods replaced 3-D space by a regular voxel grid over which CNNs can be more easily applied. Among these is
- VoxelNet:
Encodes voxel features using deep networks and allows end-to-end learning.
- SECOND:
Enhances voxel encoding for speed and accuracy.
- 3DSSD:
Single-stage detection network using voxelization to achieve real-time detection.
Advantages
The grid structure of voxel makes it a very natural candidate for applying CNNs in order to achieve high detection accuracy. The voxel- based methods can easily be combined with existing 2D-based detection methods, thereby allowing multi-modal detection.
Disadvantages
Probably the most memory-consuming and computationally expensive voxel- based techniques, especially in the case of higher solution voxels, which often prevent real-time applications and scalability.
RGB-D Based Methods for 3D Object Detection
RGB-D based techniques combine RGB images and depth information, making use of both color and spatial cues. Among them are notable methods such as:
- Frustum PointNet:
It first detects regions of interest using 2D object detection and then uses PointNet to detect 3D objects within these regions.
- VoteNet:
Combines depth information with voting algorithms to predict the locations of objects.
Benefits
These techniques take into account both color and depth information, and they increase detection accuracy, especially in complex textures as well as in the presence of poor lighting conditions within a scene.
Drawbacks
In many such devices, their state can be disadvantageous since noise or low resolutions are likely to cause incorrect detection. The technique to handle occlusions is still challenging, as each object can overlap with others or hide any other object.
Hybrid Techniques for 3D Object Detection
Hybrid techniques combine the point clouds, voxels, and RGB-D to enhance accuracy in detection. MV3D and AVOD are examples of such techniques where multiple data representations are utilized for detection in harsh environments.
Hybrid techniques achieve better accuracy and robustness due to integration video analysis of multiple representations. They function well in complex scenes when other single-method approaches may fail.
Challenges
First of all, it becomes relatively difficult to implement in real-time scenarios because the main issue is increased model complexity. In addition, heterogeneous data may pose a problem in terms of data fusion and alignment.
Recent Advances on 3D Object Detection
Transformer-based Models
For instance, some recent advancements built on the lines of models which have been known to capture long-range dependencies in data, including transformer-based models. The model comes better knowledgeable about the spatial relations that help in increasing the precision of detection by bringing transformer knowledge to 3D data.
Emerging Trends in Self-Supervised and Semi-Supervised Learning
Techniques self and semi-supervised are gaining their ground in 3D object detection. This kind of approach significantly reduces the requirement of pre trained model and a large annotated dataset as models can learn from the unlabelled data, which furthermore enhances scalability.
Light and Efficient Models
Recent advances in efficiency in models have led to light models that run on edge devices. Such models enable the possibility of real-time 3D object detection in applications such as autonomous drones, mobile robots, and AR devices.
Datasets and Benchmarks for 3D Object Detection models
Popular Datasets
There are several other architectures and large-scale datasets in wide use to train as well as benchmark 3D object detection, mainly:
This includes
- KITTI:
A dataset feature maps for self-driving cars, point clouds and images from the scenarios of real-world driving.
- Waymo Open Dataset:
A large-scale dataset for 3D detection and tracking in autonomous driving.
- NuScenes:
It is a multi-modal dataset of LiDAR, radar, and camera data.
- ScanNet:
An interior scene understanding dataset that focuses on RGB-D images and 3D reconstructions.
Importance of Benchmarks in 3D object detection models
Standardized benchmarks become important tests for 3D object detection methods since it gives a fair structure for the comparison between models and pushes the forward motion in the field.
Challenges in Data Set Preparation
The preparation of diverse datasets in 3D is difficult due to the nature of difficulty from capturing 3D data in various environments and conditions. Dataset collection becomes challenging because of factors like occlusion, illumination, or restrictions due to sensor limits.
Challenges in 3D Object Detection
Data Sparsity and Occlusion
For real-world scenarios, the data is sparse in many instances, and some objects may be occluded partially or wholly. This leads to incorrect identification and classification of objects by the model.
High Computation Needs
3D object detection have massive requirements in terms of computation both during training as well as during inference time. High-resolution data, complex architecture, and large datasets mandate tremendous computational power.
Scalability and Real-Time Processing
Balancing Model Complexity with the Need for Real-time Applications
The balancing of model complexity usually presents a challenge so that it is optimized for real-time applications. Models have to be tuned to run efficiently on edge devices or real-time systems such as autonomous vehicles.
Generalization Across Environments
Models can be trained in specific environments but fail to generalize to new scenarios, such as different weather conditions, sensor types, or geographic locations. The important challenge is to develop models that can adapt to different environments.
Applications of 3D Object Detection models
Autonomous Vehicles
3D object detection is inherent in self-driving cars in which 3D object and pedestrian detection, is a constituent part of self-driving car systems. It makes the cars detect and trace humans, bicycles, automobiles, and other obstructions.
Once the location and motion of those objects in three dimensions are known, self-driven automobiles can take immediate decisions on evasion and alternate paths in intricate environments.
For instance, Tesla's Autopilot as well as Waymo utilizes 3D object detection heavily in tracking objects, lanes, and path planning.
Robotics
In robotics, 3D object detection can assist in scene understanding and perform object detection and manipulation, both of which are important in warehouse automation, industrial robots, and healthcare assistance robots.
The interaction of the robot with their environment is dynamic and often unpredictable.
Through computer vision and the assistance of 3D object detection, robots can accurately perceive and locate objects in three-dimensional space and manipulate them as required for picking and placement or navigation in cluttered environments.
AR/VR and Gaming
3D object detection in AR and VR applications enables real-world settings and virtual environments to blend in one another.
With accurate 3D object detection model, virtual objects can dynamically engage with the real world.
For instance, in AR applications such as Microsoft's HoloLens, 3D object detection enables users to use holograms in a real-world setting that uses virtual objects responding to real-world surfaces and user gestures.
Healthcare
In medical area, 3D object detection is revolutionizing the diagnostics as well as surgery. Medical imaging technologies like CT scans, MRIs, and 3D ultrasounds generate three-dimensional data which are analyzed for anomalies such as tumors or damage to an organ.
It has 3D and other object detection methods and techniques facilitating automatically identifying those important features for quicker diagnosis with the increased accuracy.
Even in robotic surgery also, this 3D object detection assists the surgical robots move and perform with increased accuracy.
Future Trends in 3D Object Detection
Multimodal Data Integration
The prospect of 3D object detection in the near future is multifaceted and will more likely relate to more interactions with multimodal data from diverse sensors, such as LiDAR, radar, cameras, and so on.
These systems are bound to improve detection accuracy by correcting disadvantages in challenging environments from a more heterogeneous set of individual sensors.
For example, in autonomous vehicles, the fusion of velocity data from the radar and depth from the LiDAR provides a better understanding of the environment and reduces errors in vehicle detection.
In real-time 3D object detection on low-power devices: Advances in deep neural architectures spur interest in developing light, efficient models for real-time 3D object detection on low-power devices such as smartphones, drones, and AR/VR headsets.
Techniques including pruning, quantization, and edge computing have been applied to reduce the computational overhead; thus, 3D object detection tasks and models can be deployed in resource-constrained environments.
Quantum Computing and Neuromorphic Computing

In the future, there is quantum computing and neuromorphic computing, both promising areas that will redesign the 3D and popular object detection algorithms.
Quantum computing, for its part, promises to radically speed up both training and inference times of 3D models so complex data might be processed at unprecedented speeds.
Finally, in this respect, neuromorphic computing will be even more efficient processing paradigm, especially in real-time applications, where low latency is critical.
Since then, detection of 3D objects has witnessed tremendous growth in the past few years primarily because of advancements in deep learning, sensor technology input image,, and computational power.
It has been integral to technologies ranging from self-driving cars to health care and robots, where machines can see and perceive their surroundings much better. Some of the principal techniques that point-based, voxel- based, RGB-D, and hybrid methods form the basis on which far more accurate and efficient detection models are built.
Conclusions
High computation requirements, data sparsity, occlusion, and real-time processing remain to be some significant challenges limiting their wider applicability across different applications.
Nevertheless, research advancements may include transformer-based models, multimodal data fusion, and even lightweight architectures, effectively subverting these challenges and pushing the boundaries of what is possible with 3D object detection.
There are prospects for the future with the advent of quantum computing and neuromorphic technologies, combined with an embrace of 3D object detection in novel industries and devices.
Thus far, the field will be allowed to revolve around its transformative role for driving innovation across industries and the way that machines will perceive and interact with three-dimensional space.